

As you start developing with the nRF5 series chips, SoftDevices, and SDKs, it's very useful to learn how errors can be discovered (and preferrably recovered from). This can be detecting something as simple as using invalid parameters to a function, or discovering when an unexpected chain of events breaks your application.
Robust application design is a broad topic, beyond the scope of this blog post. This post is meant as an introduction to nRF-specific error handling, which is useful to understand when developing using Nordic SoftDevices and SDKs.
This blog post is split into two main parts:
- Error detection for development purposes
- Error detection and recovery during runtime
Both parts are based on the standard SoftDevice and SDK error handling. Note that at the time of writing SDK v11.0.0 is the most recent SDK version. This version has made some changes to the error handling specifics, although the general principle remains the same.
Recommended reading:
- Error detection and logging for development purposes =======
The most important part of error detection is to actually check function return values. Most of, if not all, the SoftDevice or SDK functions returns an uint32_t which indicates whether or not the function was successful. If this value is ignored, you will have a hard time figuring out what has gone wrong. Any non-zero return value indicates a problem.
Function error checking
The SDK has a set of functions and macros that facilitates checking of return values, called the Error module. Add app_error.h and app_error.c to your path and object list in order to start using these functions, and make sure you've defined the DEBUG symbol.
This module consists of two parts:
- An error handling function, defined as weak so it can be overriden
- Error checking utility macros that calls the error handling function when needed.
The default error handling function (in app_error.c) looks like this:
/**@brief Function for error handling, which is called when an error has occurred.
*
* @warning This handler is an example only and does not fit a final product. You need to analyze
* how your product is supposed to react in case of error.
*
* @param[in] error_code Error code supplied to the handler.
* @param[in] line_num Line number where the handler is called.
* @param[in] p_file_name Pointer to the file name.
*
* Function is implemented as weak so that it can be overwritten by custom application error handler
* when needed.
*/
/*lint -save -e14 */
void app_error_handler(ret_code_t error_code, uint32_t line_num, const uint8_t * p_file_name)
{
error_info_t error_info =
{
.line_num = line_num,
.p_file_name = p_file_name,
.err_code = error_code,
};
app_error_fault_handler(NRF_FAULT_ID_SDK_ERROR, 0, (uint32_t)(&error_info));
UNUSED_VARIABLE(error_info);
}
The function above calls app_error_fault_handler(), which can be overridden in your application code:
__WEAK void app_error_fault_handler(uint32_t id, uint32_t pc, uint32_t info)
{
// On assert, the system can only recover with a reset.
#ifndef DEBUG
NVIC_SystemReset();
#else
#ifdef BSP_DEFINES_ONLY
LEDS_ON(LEDS_MASK);
#else
UNUSED_VARIABLE(bsp_indication_set(BSP_INDICATE_FATAL_ERROR));
// This call can be used for debug purposes during application development.
// @note CAUTION: Activating this code will write the stack to flash on an error.
// This function should NOT be used in a final product.
// It is intended STRICTLY for development/debugging purposes.
// The flash write will happen EVEN if the radio is active, thus interrupting
// any communication.
// Use with care. Uncomment the line below to use.
//ble_debug_assert_handler(error_code, line_num, p_file_name);
#endif // BSP_DEFINES_ONLY
app_error_save_and_stop(id, pc, info);
#endif // DEBUG
}
Note the #ifndef DEBUG. If DEBUG is not defined you will not get as much information regarding the error, and a CPU reset is immediately triggered.
Knowing the behavior of these functions is important, as this is the standard error handling function for all SDK examples. Note that SDK examples does not have the DEBUG symbol defined by default.
With knowledge of the error handling functions, the next step is to call them at appropriate times. This is where the utility macros come in handy:
APP_ERROR_CHECK(ERR_CODE)
APP_ERROR_CHECK_BOOL(BOOLEAN_VALUE)
Simply call APP_ERROR_CHECK() every time you call a function that returns a status code. For example:
uint32_t err_code;
err_code = softdevice_enable(&ble_enable_params);
APP_ERROR_CHECK(err_code);
If err_code equals 0 (NRF_SUCCESS) nothing happens, but once a non-zero value is returned, the error handling function gets called, listing the error value, line number, and file name where the error was triggered.
In a development environment, it is useful to somehow notify the developer whenever an error happens. This can be done via a debugger breakpoint in the error handling function, LED blinking, UART/Segger RTT/SWO printouts, or similar.
Once an error code is returned, you must figure out what the error means. Ranges for the error values returned by SoftDevice or SDK functions are defined in the following files:
- nrf_error.h
- sdk_errors.h
Note that individual components of the SoftDevice or SDK APIs lists their own error values based on these ranges.
For example, if softdevice_enable() returns error value 0x0007 we can find the corresponding error string in nrf_error.h:
#define NRF_ERROR_BASE_NUM (0x0) ///< Global error base
(...)
#define NRF_ERROR_INVALID_PARAM (NRF_ERROR_BASE_NUM + 7) ///< Invalid Parameter
SoftDevice Faults
When certain unrecoverable errors occur within the application or SoftDevice, the fault handler will be called. This fault handler function is passed to the SoftDevice during initialization (sd_softdevice_enable().
SoftDevice faults are different from the application-level error checking as they are asynchronous. However, the SDK uses the same error handler for both error types, so you don't have to take any particular considerations in order to detect these. As these errors are generated within the SoftDevice, you won't be able to easily trace back the cause of the error. Using Devzone or Nordic MyPage support are useful resources in this case.
HardFaults
A HardFault is one of several ARM Cortex-M faults that can be generated when the applications performs an illegal operation. In effect it is a high-priority interrupt that halts the normal flow of code execution, notifying you that something has gone wrong.
There are a number of things that can cause a HardFault, depending on the CPU architecture:
- ARM Cortex-M0 Fault Handling (applicable to nRF51)
- ARM Cortex-M4 Fault Handling (applicable to nRF52)
Additionally, the SoftDevice can generate a HardFault when the application misbehaves, such as accessing memory or hardware blocks reserved by the SoftDevice.
When a HardFault is generated, HardFault_Handler() is called. By default, this is implemented as a while(forever) in arm_startup_nrf5x.s:
HardFault_Handler\
PROC
EXPORT HardFault_Handler [WEAK]
B .
ENDP
In order to get some useful information regarding what caused this error, one should override the weak HardFault_Handler implementation with an application-specific one. As with any other interrupt in the ARM Cortex core, the instruction pointer gets pushed onto the stack when a HardFault occurs. Retrieving the address of the instruction which caused the error is very helpful.
The code below can be used to fetch the offending instruction:
void HardFault_Handler(void)
{
uint32_t *sp = (uint32_t *) __get_MSP(); // Get stack pointer
uint32_t ia = sp[12]; // Get instruction address from stack
printf("Hard Fault at address: 0x%08x\r\n", (unsigned int)ia);
while(1)
;
}
With the instruction address one can use the debugger to find the offending instruction. Example using Keil:
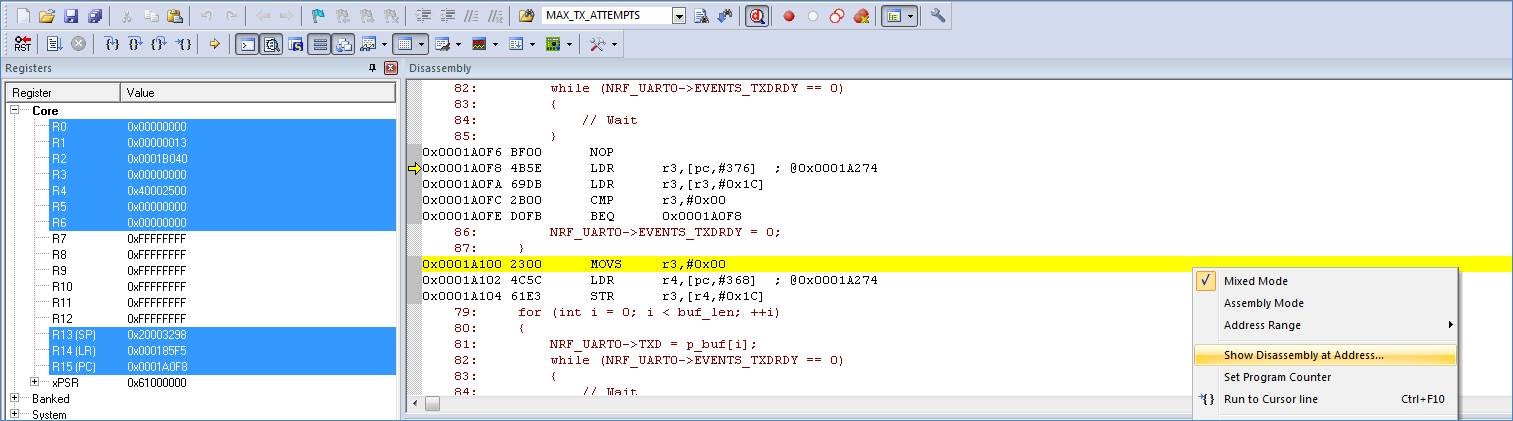
- Error detection and recovery during runtime ======= As mentioned initially, this blog post is not intended to discuss good design practices when developing robust applications. Consider these tips the bare minimum.
Function error checking
In many cases it is useful to filter out and act on certain errors returned by SDK and SoftDevice functions in addition to calling the APP_ERROR_CHECK() macro. Due to the asynchronous nature of BLE, events can happen suddenly and application-level state variables won't be updated until the SoftDevice events are processed by the application.
As an example, consider the case where the application is trying to send data to a peer device using the Notification mechanism. The underlying SoftDevice function is sd_ble_gatts_hvx() which can return a number of potential error codes. Many of these are static errors related to function parameters, while others are related to the dynamic state of the SoftDevice. It would be useful to handle at least simple cases, such as the transmit buffers are full and when the link has unexpectedly been disconnected:
err_code = sd_ble_gatts_hvx(conn_handle, p_hvx_params);
if (err_code == NRF_ERROR_INVALID_STATE)
{
// Link disconnected or data transmission not enabled by peer
// TODO: Stop trying to send data until link has been re-established, or peer enables transmissions
}
else if (err_code == BLE_ERROR_NO_TX_PACKETS)
{
// SoftDevice transmit buffers are full. This could indicate poor connectivity or an imminent disconnect.
// TODO: Decide whether the data that was attempted sent should be buffered in an application buffer or thrown away.
}
else
{
APP_ERROR_CHECK(err_code);
}
Error handler function override
In cases where the error handler is triggered, either by the APP_ERROR_CHECK() macro or caused by a SoftDevice error callback, the default error handler function in app_error.c should be overridden to perform whatever application-specific recovery functions that are needed. This can be ensuring connected hardware such as sensors, servos, FETs, etc., are in a safe state until the application has recovered.
The bare-minimum recovery would be to simply reset the CPU, trusting that the cause of the error was a rare occurrence. The danger with this approach is that an error happening during the initialization phase can lead to a loop of CPU resets.
A safer approach is to revert any dynamic data, such as bonding information, to a known good state when certain errors occur.
HardFaults
Again, the bare minimum would be to simply reset the system when a HardFault, or in the case of Cortex-M4 another Fault, happens. This won't remove the underlying cause of the fault, which is a problem if the underlying cause triggers frequently.
Note that nRF52 SoCs using the Cortex-M4F CPU have more Fault types than the nRF51, which only has the HardFault. All Faults are by default implemented as while(true) loops in the SDK.
Watchdog
Checking errors and waiting for error callbacks doesn't cover all error cases. Sometimes your application can get into a deadlock, or maybe a stack overflow causes a CPU lockup situation. In such cases the watchdog can help recover the system, simply by resetting the CPU and all hardware registers.
The watchdog is a hardware block containing a hardware timer that counts down from a configurable initial value. Once the counter reaches zero, the system is reset. The application can reset the timer ("feeding/kicking the watchdog") to the initial value to prevent the reset. If the application is unable to reset the watchdog timer (because of a fault) the counter will reach zero and the system be reset.
Some finesse goes into deciding when the watchdog should be fed, with the goal of catching as many faults as possible without triggering unwanted resets. One approach is to run the feeding as an app_timer timer instance, which runs at the lowest interrupt priority. Note that if there are software routines running from the main context (Cortex Thread mode) it would be safer to run the watchdog feeding routine in the same context.
The watchdog hardware is described in the nRF51 Reference Manual and nRF52 Product Specification.




