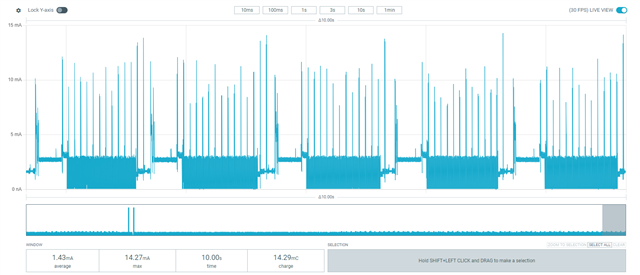
Hi,
We are facing a critical power consumption issue in our nRF52-based Zephyr application, where some devices randomly enter a high-power consumption state (~80+ µA) instead of the expected 35-40 µA in idle mode.
Impact:
- Users are experiencing severe battery drain.
- Expected battery life has reduced to less than half in affected devices.
- The issue is random, making it difficult to track and resolve.
This issue occurs in multiple scenarios:
- On runtime under certain conditions
- After a reset
- After a firmware update
- Randomly, without a clear trigger
We have a global float variable: float total_current = 0.0f;
-
This variable is modified in two places:
- A worker thread
- A BLE command receive event handler
- When we commented out the function call in the BLE handler and flashed the firmware, the power consumption increased unexpectedly.
- We initially suspected FPU lazy stacking or context-switching issues but could not confirm.
- However, aligning the float variable using
__aligned(8)or declaring it locally inside the function completely eliminated the power issue and we thought this will fix the issue and added __aligned(8) for all global float variables. - This led us to suspect a floating-point-related issue, but the behavior reappeared when we initialized an atomic variable globally, like this atomic_t is_bat_chargin = ATOMIC_INIT(0);
and used it inside some timers and functions.
Need help with the following,
- Why does initializing a global float (or even an atomic variable) sometimes cause a high-power state?
- Could this be related to FPU context switching, stack alignment, or something else in Zephyr/nRF52?
- Why does aligning the float or declaring it locally fix the issue?
- Is there a better way to avoid such random power increases when using floating-point operations and atomic variables in Zephyr?
- Is there any extra configuration, debug setting, or power profiling tool we should enable to track down the exact cause of this issue?
Additional info
- SoC: nRF52840
- Zephyr Version: 2.6.1
- CONFIG_FPU=y , CONFIG_FPU_SHARING=y
- Optimization Level in Build: Optimize for size
- Power Measurement Setup: Using a power profiler tool
This is a critical issue affecting production devices, and we urgently need guidance to identify the root cause and resolution.
Appreciate any insights into this issue! Is there anything extra we should check or enable to debug this further?
Thanks,
Vishnu