
I have 25Q64 SPI flash chip connected to SPI bus. Unfortunately it works too slow even with using IRQ routine via SPI0_TWI0_IRQHandler (everything done like in example spi_master-pca10028). Typical timing diagram:
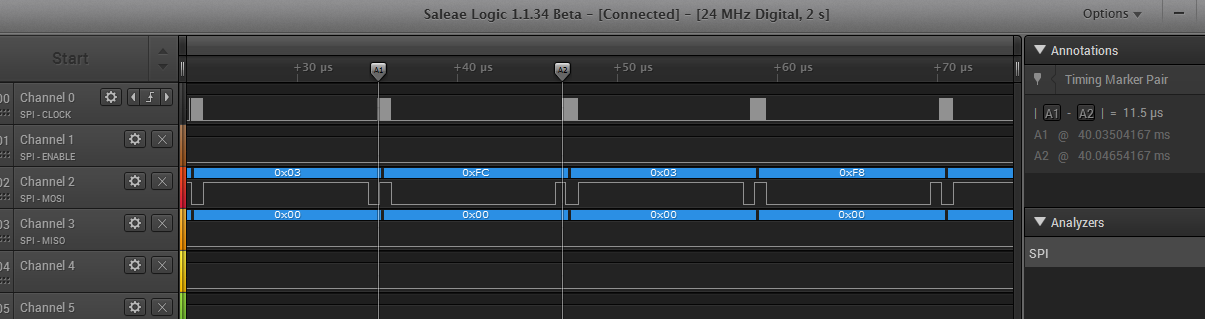
Is this problem in SPI hardware implementation or interrupt routing via softdevice? Can you propose any ways to speed up SPI throughput? Do you have correct double-buffering example with checking if TX buffer ready for 1 or for 2 bytes? As a temporary solution I've use trick with delay:
for (int i = 0; i<datalen; i++) {
MEM_SPI->TXD = data[i];
nrf_delay_us(1);
}
It works better, but I'm not sure if this way productive and stable enough for production:
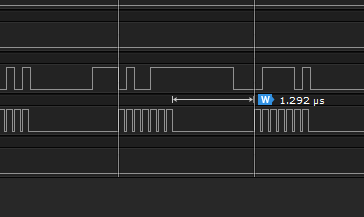
If this way Ok, I'll use my own nrf_delay_us with fewer NOP's :)
