Hi,
We have one customer having two CoAP hosts and some CoAP clients in the form of wireless sensors. The sensors are paired to a single host. The pairing is actually in the app level, where the sensor discovers the network IP of the host in pairing host. All the devices have the same PANID and network key.
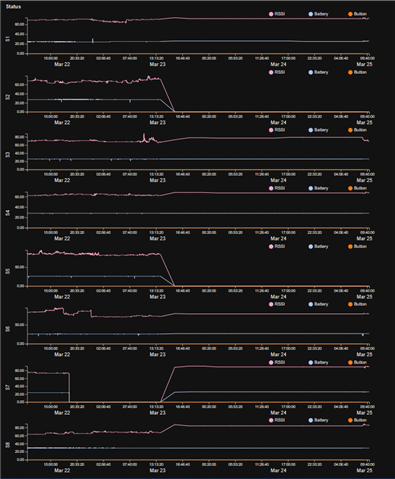
Recently we have seen a scenario where some sensors seemingly stopped communication with the paired host. By looking at the RSSI graphs, we thought is this caused by a sensor constantly swinging back and forth between two hosts (one host acting as a router). We dont have access to the CLI interface of the hosts as this is a remote site. We see the Sensor RSSI reported back. This is its RSSI with the router/leader immediately connected to at the time.
Any ideas?
Cheers,
Kaushalya