
Hi,
we've run into an issue using the SPI master (SPIM). We got the NRF5340 connected to our FPGA using 2 spi busses. The NRF is SPI master on one bus and SPI slave on the other. For testing, we're sending quite some transactions (1800/s receives on the slave, 400/s sends on master). Both busses only have MOSI, no MISO (so both are one-way). We use interrupts to notify the main code only, all SPIM transactions are started outside interrupts.
We always send/receive 7 bytes frames. Since we're testing, we also send known content (a header + cmd + sequence number + trailer). What we see if that sometimes (in order of 1:100.000) that the SPI master 'forgets' to send the last clock cycle of a transaction. So instead of sending 56 clock cycles (=7 bytes * 8)), it only sends 55. Other times it add 7 cycles.
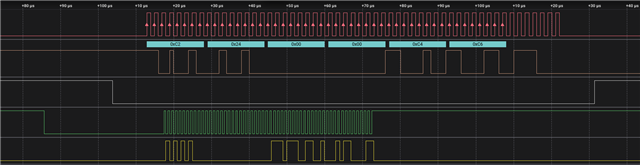
The top 3 (Red/Brown/white) form the SPI_master's bus. The bottom 2 (missing CS there because we needed pin on logic analyser for other signal) show the incoming SPI transaction from the FPGA. The logic analyser marks all the rising flanks on the RED clock where it samples. The last byte only has 7 bits, so they are not marked.
Zooming in on the top-left part:
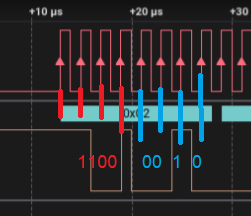
So the signal should only change on the falling edges of the clock and be samples (by the FPGA/logic analyser) on the rising edges. We expect the data to be C9 12 at start, but it's not. The small brown column at 19 usec is weird! It's only half a clock cycle long and the signal changes during the rising-edge of the clock?!?!
I suspect that's where the missing last clock cycle/bit gets 'eaten'. The 2nd byte is indeed shifted 1 bit (12 -> 24).
We have several different captures that show this behaviour.
We upgraded to NRFX 3.3 (latest), this seems to lower the frequence of this happening, but it still does. Disabling BLE did not change anything.
I suspect that sometimes, an incoming SPI slave transaction corrupts the data/state of the SPI master? But this is speculation.
Since the DevZone support was really helpful in solving our other issues, i hope you can repeat that again 

