Hi
I am using nRF52832, S132 / SDK17, implementing an algorithm requiring some math,
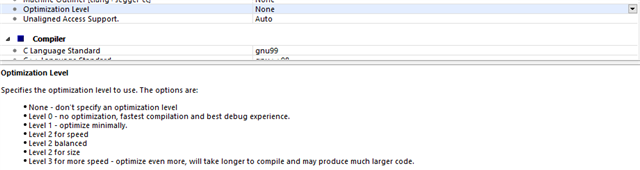
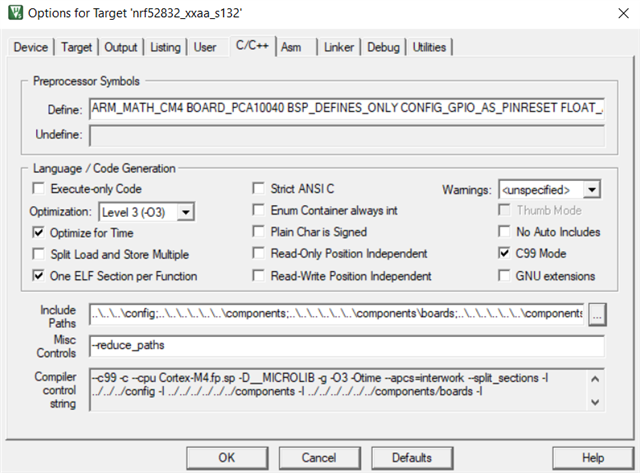
for example I am doing a matrix multiplication with about 800 float multiplications, I understand that a multiplication taking 3 cycles from the ARM-M4, working with 32MHz; and optimizing for time, I am seeing it 2400 cycles to take more than 200us -Does that make sense?
is there some way (not algorithmically that is) to improve those performances? some other optimizing flag to be raised, FPU enableing? a way to allocate the memory to be more efficiently accessed?
Is there some example/reference you can refer me to?
Thanks!