
Summary
I'm finding the DM subsystem's individual ranging calculations fail around 10% of the time (in line-of-sight conditions, around one meter apart). Is this expected?
Test Setup
I have two nRF5340's running a (slightly) modified version of the "nrf_dm" sample with all of the default Kconfig options and Bluetooth scan/advertising settings, except for the following:
CONFIG_DM_TIMESLOT_QUEUE_COUNT_SAME_PEER=1
CONFIG_LOG_MODE_DEFERRED=y

- I'm doing one-directional ranging and using MAC address filters to know when to start ranging.
- Environment is a typical office space with 10-20 nearby laptops and a couple of Wi-Fi routers
- The nRF5340 on the left is the "reflector" and is only advertising.
- The nRF5340 on the right is the "initiator" and is only scanning.
- Most importantly: The application logic ensures only one ranging calculation happens every 3 seconds:
- the "reflector" turns on advertising (timeout = 1000ms) and starts a 3 second timer
- the "reflector" stops advertising after the first call to dm_request_add()
- when the timer expires, the "reflector" starts advertising again and the process repeats
Test Results
I get slightly different results depending on which device's log output I analyze. You can see from the data below that I tracked the failure types to help isolate ranging failures and ignore synchronization failures (e.g. "reflector" advertisement was never scanned by the "initiator").
From the "initiator" perspective:
From the "initiator" perspective:
Total Failures: 111
Ranging Failures: 58 i.e. data_ready() never called
CRC Failures: 15 i.e. Quality == "crc fail"
Scanning Failures: 38 i.e. scan_filter_match()/data_cb() never called
Ranging Requests: 699 i.e. dm_request_add() was called
Ranging Successes: 626 i.e. Quality == "ok"
Looking at just (Ranging Failures) / (Ranging Requests): 8.3% failure rate
Looking at (Ranging Failures + CRC Failures) / (Ranging Requests): 10.4% failure rate
Looking at (Ranging Failures + CRC Failures) / (Ranging Requests): 10.4% failure rate
From the "reflector" perspective:
Total Failures: 110
Ranging Failures: 74 i.e. data_ready() never called
CRC Failures: 11 i.e. Quality == "crc fail"
Scanning Failures: 25 i.e. adv_scanned_cb() never called
Ranging Requests: 712 i.e. dm_request_add() was called
Ranging Successes: 627 i.e. Quality == "ok"
Looking at just (Ranging Failures) / (Ranging Requests): 10.4% failure rate
Looking at (Ranging Failures + CRC Failures) / (Ranging Requests): 11.9% failure rate
Looking at (Ranging Failures + CRC Failures) / (Ranging Requests): 11.9% failure rate
Logic Analyzer
I'm seeing two main types of "ranging" failures in the logic analyzer. Note that I added a "success" GPIO that is toggled when the data_ready() callback indicates a ranging event completed.
Success
For comparison purposes, you can see both "reflector" (blue) and "initiator" (red) get the dm request, start ranging, and get a result.

Failure Mode #1 - Short Ranging Window
The time spent "ranging" on both the "reflector" (blue) and "initiator" (red) is truncated in this failure mode. You can see the ranging window is within a few milliseconds, and neither device gets results.
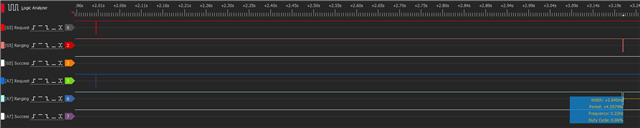
Failure Mode #2 - Long Ranging Window
The time spent "ranging" on both the "reflector" (blue) and "initiator" (red) is NOT truncated in this failure mode. You can see the ranging window is within a few dozen milliseconds, and neither device gets results.



