Hi!
Can you please help me identify what is causing this issue and/or provide more info about this:
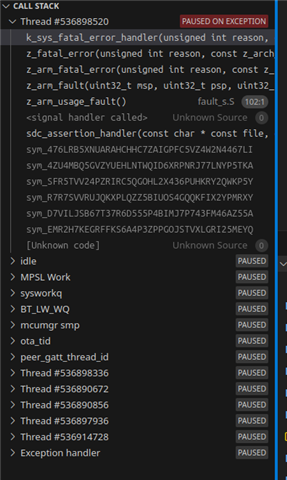
[00:04:23.038,330] \033[1;31m<err> bt_sdc_hci_driver: SoftDevice Controller ASSERT: 53, 296\033[0m
[00:04:57.431,335] \033[1;31m<err> os: ***** HARD FAULT *****\033[0m
[00:04:57.431,335] \033[1;31m<err> os: Fault escalation (see below)\033[0m
[00:04:57.431,365] \033[1;31m<err> os: ARCH_EXCEPT with reason 3
\033[0m
[00:04:57.431,365] \033[1;31m<err> os: r0/a1: 0x00000003 r1/a2: 0x00000000 r2/a3: 0x0001981b\033[0m
[00:04:57.431,396] \033[1;31m<err> os: r3/a4: 0x00000000 r12/ip: 0x20000ab0 r14/lr: 0xffffffff\033[0m
[00:04:57.431,396] \033[1;31m<err> os: xpsr: 0x41000011\033[0m
[00:04:57.431,396] \033[1;31m<err> os: r4/v1: 0x20015c70 r5/v2: 0x0003370d r6/v3: 0x0000000a\033[0m
[00:04:57.431,427] \033[1;31m<err> os: r7/v4: 0x20015c70 r8/v5: 0x20001944 r9/v6: 0x2000e204\033[0m
[00:04:57.431,427] \033[1;31m<err> os: r10/v7: 0x200008bc r11/v8: 0x00000000 psp: 0x20015f40\033[0m
[00:04:57.431,457] \033[1;31m<err> os: EXC_RETURN: 0xfffffff1\033[0m
[00:04:57.431,457] \033[1;31m<err> os: Faulting instruction address (r15/pc): 0x00033744\033[0m
[00:04:57.431,488] \033[1;31m<err> os: >>> ZEPHYR FATAL ERROR 3: Kernel oops on CPU 0\033[0m
[00:04:57.431,518] \033[1;31m<err> os: Fault during interrupt handling
\033[0m
[00:04:57.431,549] \033[1;31m<err> os: Current thread: 0x2000ae30 (unknown)\033[0m
[00:05:09.972,747] \033[1;31m<err> fatal_error: Resetting system\033[0m
When this happens it is in the process of uploading a new fw thru mcumgr image group, upload command.
I haven't been able to fully verify this but I think this affected by updating to SDK 2.6.0 (from 2.4.0).
That code part is unchanged before and after the SDK update except that "zcbor_new_decode_state" had two new parameter which we have set to NULL and 0 (after comparing how some examples had changed between sdk versions).
BR,
Mårten