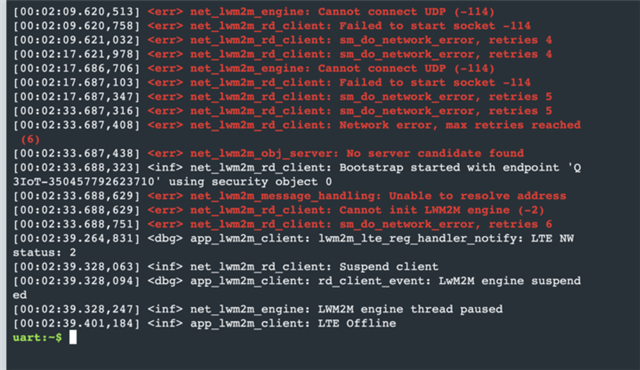
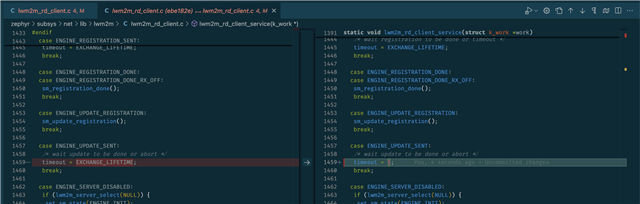
We have noticed that several of our nRF9160 in production have problem with reconnecting to the LTE-M network after temporarily losing connection. We have tried reproducing this issue by deactivating the sim for about 10 seconds and then activating it again. After the default six retries it gives up and stop trying to reconnect to the network. the only way we can achieve a connection is if we do a sys_reboot() or a hard reboot with watchdog. Why is the reconnect attempts not enough? Why do we have to force a reboot? Attached are relevant logs.