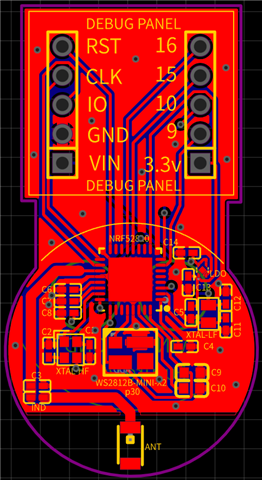
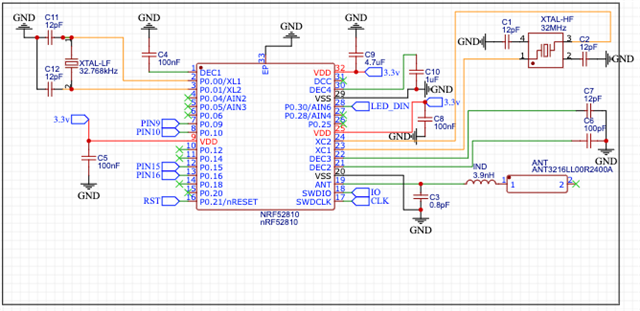
I'm working on a personal project and have designed and printed a small prototype board containing an nrf52810, external antenna, couple of crystals, and a ws2812b onboard, along with a handful of helpful breakout headers for programming and debugging
I can get GPIO working fine (I can toggle offboard leds on demand), and have full control over the ws2812b led, but every single attempt to get a working bluetooth (ble) signal broadcasting is failing. Sometimes the device is stack-overflowing, sometimes it's just erroring out, and sometimes it just ... doesn't say why it's not broadcasting. Note that as far as my circuit goes - I know that it likely isn't great, and won't result in amazing range or anything - I don't mind that as I only need _some_ range so I can test things.
Can someone take a look at the circuit and sample code and give me some insight into why this might not be playing ball? Every time I think it's broadcasting, I can't see the device when I scan using my iPhone and the nrf Connect mobile app.
Versions I'm using:
-
M2 Macbook Pro
-
`make` or `west build` both work for building the project
-
STLink V2 (a cheap chinese device running its latest firmware)
-
Openocd v0.12.0 (for flashing the chip - which works great)
-
SoftDevice s112 (v7.2.0) (only used when I'm building the examples from the old nRF5 SDK ... which also has this exact same problem of no signal being detected)
-
NCS v2.6.1
-
Zephyr v3.5.99 (bundled with ncs v2.6.1)
-
Device tree is very simple and is a custom board that extends `<nordic/nrf52810_qfaa.dtsi>` to enable a small handful things like `gpiote` and the `flash0` partitions
My board `defconfig` and project `prj.conf` files are pretty simple too, but I've attached a very simple `main.c` to show my workings so far.
Any help at all on this would be appreciated. Aside from help from friends in the know, I'm fully self taught on PCB design, component selection, and coding on this thing. Basically: I don't know what I don't know because I don't know anything.
#include <zephyr/kernel.h>
#include <zephyr/logging/log.h>
#include <zephyr/bluetooth/bluetooth.h>
#include <zephyr/drivers/gpio.h>
LOG_MODULE_REGISTER(main, CONFIG_LOG_DEFAULT_LEVEL);
#define DEVICE_NAME CONFIG_BT_DEVICE_NAME
#define DEVICE_NAME_LEN (sizeof(DEVICE_NAME) - 1)
#define LED_RED_NODE DT_ALIAS(led0)
#define LED_BLUE_NODE DT_ALIAS(led1)
static const struct gpio_dt_spec led_red = GPIO_DT_SPEC_GET(LED_RED_NODE, gpios);
static const struct gpio_dt_spec led_blue = GPIO_DT_SPEC_GET(LED_BLUE_NODE, gpios);
static void init_leds(void)
{
gpio_pin_configure_dt(&led_red, GPIO_OUTPUT_ACTIVE);
gpio_pin_configure_dt(&led_blue, GPIO_OUTPUT_ACTIVE);
}
static void flash_leds(int red, int blue, int msec_pause) {
if (red > 0) gpio_pin_set_dt(&led_red, 1);
if (blue > 0) gpio_pin_set_dt(&led_blue, 1);
k_sleep(K_MSEC(msec_pause));
if (red > 0) gpio_pin_set_dt(&led_red, 0);
if (blue > 0) gpio_pin_set_dt(&led_blue, 0);
k_sleep(K_MSEC(msec_pause / 2));
}
static const struct bt_data ad[] = {
BT_DATA_BYTES(BT_DATA_FLAGS, BT_LE_AD_NO_BREDR),
BT_DATA(BT_DATA_NAME_COMPLETE, DEVICE_NAME, DEVICE_NAME_LEN),
};
struct bt_data sd[] = {
BT_DATA(BT_DATA_NAME_COMPLETE, DEVICE_NAME, DEVICE_NAME_LEN),
};
int main(void)
{
int err;
LOG_INF("App boot");
init_leds();
flash_leds(1, 1, 500);
err = bt_enable(NULL);
if (err) {
LOG_ERR("Bluetooth init failed (err %d)", err);
return -1;
}
LOG_INF("Bluetooth initialized");
flash_leds(1, 1, 500);
err = bt_le_adv_start(BT_LE_ADV_NCONN, ad, ARRAY_SIZE(ad), sd, ARRAY_SIZE(sd));
if (err) {
LOG_ERR("Advertising failed to start (err %d)", err);
return -1;
}
LOG_INF("Advertising successfully started");
flash_leds(1, 1, 500);
flash_leds(1, 1, 500);
while(1) {
k_sleep(K_MSEC(500));
flash_leds(0, 1, 500);
}
}
|