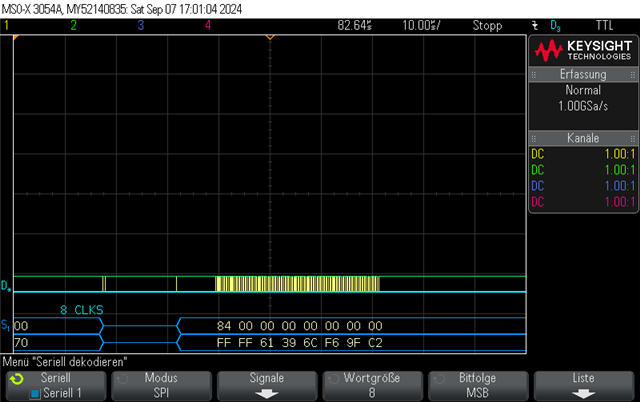
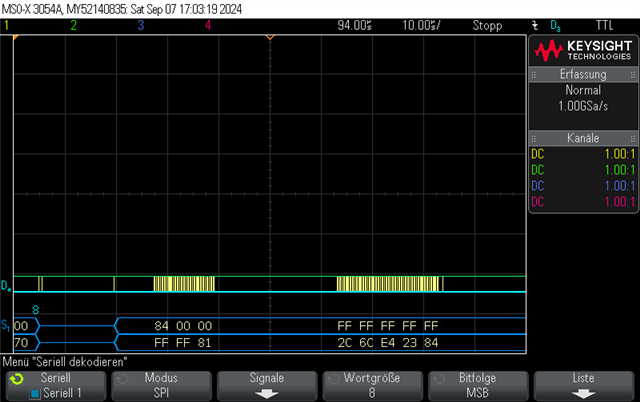
Hi, I am wondering if anyone with SPI expertise can answer this Q, I'm using an nRF52840 with spi_transceive_dt()
In my devicetree I've configured SPIM on SPI3 to talk to a sensor at 10MHz.
I am simply doing a register read to a sensor device. So calling spi_transceive_dt() with 1 Tx byte and 2 Rx bytes (the sensor requires 1 dummy byte for each read). It responds correctly with 0x00, 0x24 and I get the data fine.
I am wondering why is there is big ~14us gap between bytes. From the red line I have highlighted, you can see SCK is just flat, waiting during this time, until it starts to clock again and we see the next byte from the slave (0x00), and then the same gap until the next byte (0x24).
I am wondering if this is to do with the MCU or some inefficiency in the SPI driver somewhere in the stack of nRFX drivers to Zephyr SPI API?