I'm using nRF Connect SDK version 2.3.0
nrf52840, and external flash - W25Q256JVEIQ.
I believe I'm running the chip at 80MHz (rated for 133),
with the qspi chip and partition set up for 100% of the available memory in bits, and Bytes, respectively.
I created my application referencing the zephyr example:
https://docs.zephyrproject.org/latest/samples/subsys/fs/littlefs/README.html
And in general, behavior is great. this seems to operate as expected. with a blank chip - it gets formatted, with a filesystem present, it automounts.
My relevant configs are:
in customboard.dts:
fstab {
compatible = "zephyr,fstab";
lfs1: lfs1 {
compatible = "zephyr,fstab,littlefs";
mount-point = "/lfs1";
partition = <&lfs1_part>;
automount;
read-size = <16>;
prog-size = <16>;
cache-size = <64>;
lookahead-size = <32>;
block-cycles = <512>;
};
};
&qspi {
compatible = "nordic,nrf-qspi";
status = "okay";
pinctrl-0 = <&qspi_default>;
pinctrl-1 = <&qspi_sleep>;
pinctrl-names = "default", "sleep";
label = "DEV_QSPI";
w25q: w25q@0 {
compatible = "nordic,qspi-nor";
reg = <0>;
label = "DEV_QSPI_FLASH";
// writeoc = "pp4io";
// readoc = "read4io";
jedec-id = [ EF 40 19 ]; // winbond W25Q
sck-frequency = <80000000>;
size = <(1024*1024* 256)>; //256 Mbit
// status = "okay";
partitions {
compatible = "fixed-partitions";
#address-cells = <1>;
#size-cells = <1>;
lfs1_part: partition@0 {
label = "ext_storage";
reg = <0x00000000 0x02000000>;
};
};
};
};
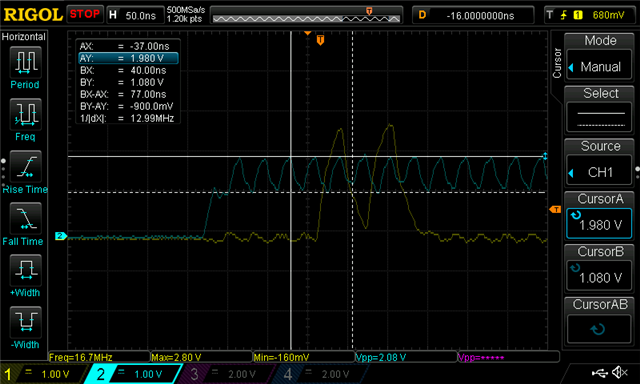
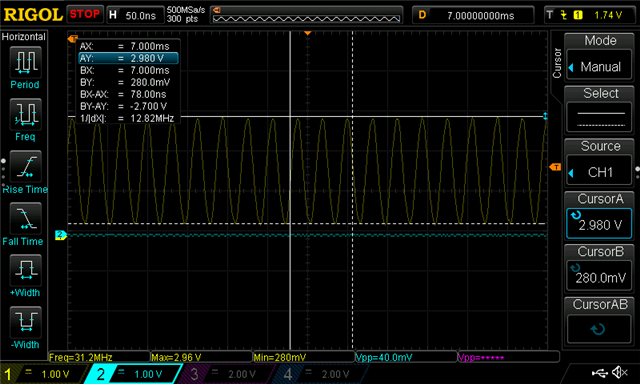
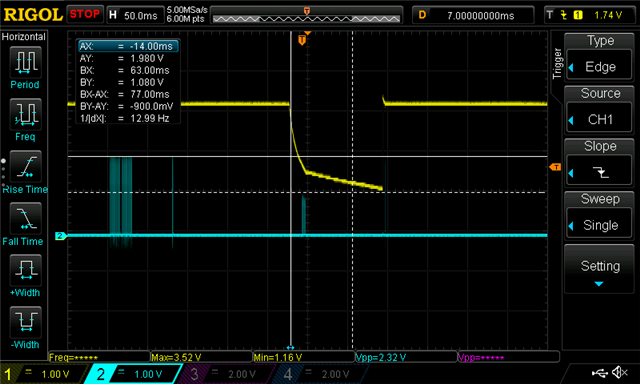
However, every once in a while, it seems that there is a glitch, reading the dir pair fails, and the whole filesystem is falsely reformatted. (reformatted when otherwise, the system was valid).
[00:00:00.010,559] <err> littlefs: Corrupted dir pair at 0 1 [00:00:00.010,559] <wrn> littlefs: can't mount (LFS -84); formatting
The glitch happens once in... somewhere between 100 and 1000 power cycles.
My understanding of littleFS makes me believe it is very unlikely that the filesystem is actually corrupted.
github.com/.../littlefs
My first thought was to replace the automount logic with something that has a bit more error checking... for example:
1. Confirm communication with the external QSPI flash is happening correctly.
2. Then attempt mount.
3. if mount fails, check some regions of the external flash data for markers which could indicate it's a completely blank chip.
4. if it's a completely blank chip, trigger format, and try mount again. (If not, just go into the application logic - there's a separate mechanism for wipe everything and reformat as a "factory reset".
However, there are other levers I could pull too.
1. Drop the clock speed of the external flash.
2. investigate other littleFS configuration options.
I did a little digging around the forum, and this seems to be unique from what I could find.
To be clear, very, very, often - almost always - the SDK works as expected, but having the filesystem get intermittently wiped clean will be a showstopper for my application.
Have you seen this before, or have any idea what could cause the issue?
My gut says this could be a power-on race condition, or relating to differences in voltage when the external flash, and nRF, recognize when power is present.
I'd rather not replace the automount code unless I need to - that seems pretty solid overall.
Thanks,
Ryan