Just for fun, I thought it'd be interesting to see how to implement a delay on the nrf52840 using the least possible power.
For any long period of time, you should use RTC, TIMER, and then put the processor into a lower power state, but I needed some tiny pauses, and I was curious about the most efficient way to do so.
Here are some measurements... I tried a few different things:
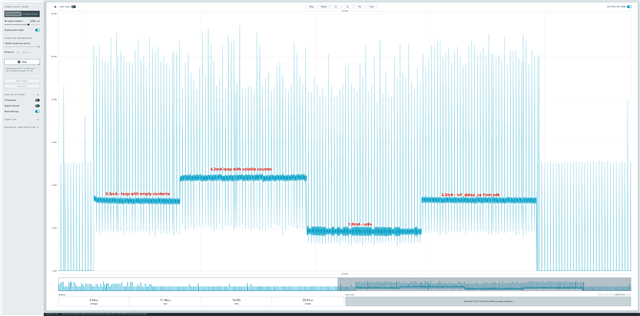
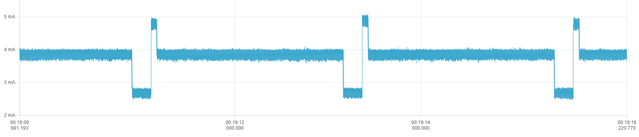
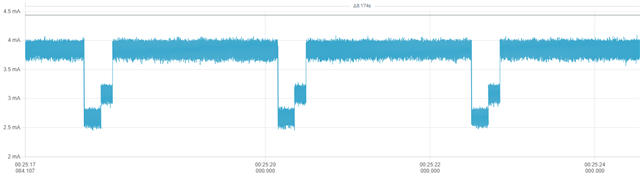
nrf_delay_us: 3.3mA
This solution: 1.9mA
The final code I'm using is this:
__attribute__((noinline)) void DelayMicros(uint32_t micros) { uint32_t count = micros; // Inline pause. // Measured at 64 cycles per loop -- at 64MHz for nrf52840, one loop is one microsecond. int a = -1; int b = 1; int c; // This is 40% lower power consumption compared to nrf_delay_us. do { asm volatile("udiv %0, %1, %2" : "+r"(c) : "r"(a), "r"(b)); asm volatile("udiv %0, %1, %2" : "+r"(c) : "r"(a), "r"(b)); asm volatile("udiv %0, %1, %2" : "+r"(c) : "r"(a), "r"(b)); asm volatile("udiv %0, %1, %2" : "+r"(c) : "r"(a), "r"(b)); asm volatile("udiv %0, %1, %2" : "+r"(c) : "r"(a), "r"(b)); } while (--count);}There's an overhead of about 14 cycles to call and return from the function and set up the variables.
Why udiv? I had a theory that if I took the instruction that took the most cycles to execute (and something that avoids accessing memory), it would avoid fetch and decode logic from running. The udiv instruction is listed as 2-12 cycles on the cortex m4 datasheet, so I've given it operands to maximize that cycle count. I have no idea if this is the reason it works better or not, but that's how I ended up trying it.
Just thought I'd share it in case anyone else wants to use it.
note: The graph was taken with BLE central & peripheral active, as I wanted to ensure long cycle count instructions didn't cause problems.