I am trying to migrate a blocking SPI transfer code to a non-blocking SPI Manager schedule call. I have 16 transfers queued up in one transaction.
When I launch it, the complete transaction takes ~300us. If I use the old code, the 16 transfers only take ~170us. Do you have any idea what may cause this? I was trying to understand the manager code, but could not see anything that would explain the slower communication.
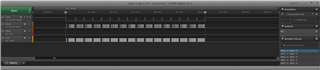
Attaching a screenshot of one transaction (using the manager):

Using raw SPI master calls:

Code snippet I am using. Note, EasyDMA is turned on:
#define TRANSACTION_QUEUE_SIZE 3
#define SPI_INSTANCE 0
static nrf_drv_spi_config_t spi_config = NRF_DRV_SPI_DEFAULT_CONFIG;
NRF_SPI_MNGR_DEF(spi_mngr, TRANSACTION_QUEUE_SIZE, SPI_INSTANCE);
static nrf_spi_mngr_transfer_t transfers[16];
static uint16_t rx_buffer[16] = {0};
...
static nrf_spi_mngr_transaction_t transaction = {
.begin_callback = NULL,
.end_callback = emg_handle_received,
.p_user_data = NULL,
.p_transfers = transfers,
.number_of_transfers = 16,
.p_required_spi_cfg = NULL};
return nrf_spi_mngr_schedule(&spi_mngr, &transaction);
Thanks!