
I am developing a Bluetooth Mesh program to run on the nRF52832 development board. I started by modifying the "nrf5_SDK_for_Mesh_v1.0.0_src\examples\light_switch\server" program which I have already tested to work the the board running the "nrf5_SDK_for_Mesh_v1.0.0_src\examples\light_switch\client" program.
I initially commented out the statement:
// ERROR_CHECK(nrf_mesh_node_config(&config_params));
so that I can step through my own codes without the mesh stack throwing exception (probably due to time out). I have added codes that will call the nrf_flash_erase() and nrf_flash_write() functions found in the nrf_flash.c file. The program works well and I can erase and program any flash memory location on the nRF52 SoC.
However, once I enable the mesh stack by allowing the statement " ERROR_CHECK(nrf_mesh_node_config(&config_params));" to run, then calling the nrf_flash_erase() will result in the program stopping at the following location 000008C8 (is this the location in the softdevice?)
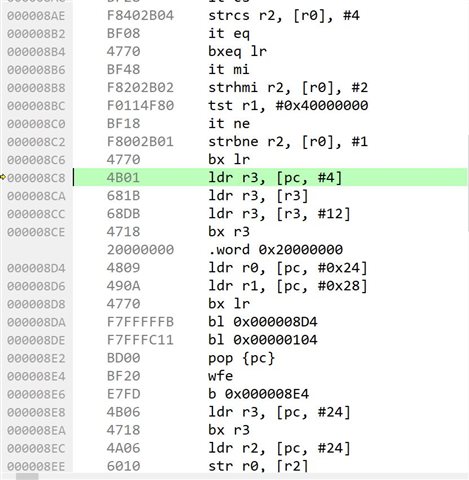
I then step through the program by pressing F10 when it stopped at the above location, after stepping pass the line at 08CE the program with restart from beginning
When I step through the nrf_flash_erase() function I noticed that once the following statement is run the program will immediately stop at the 08C8 location as shown in the above screen capture.
NRF_NVMC->CONFIG = (NVMC_CONFIG_WEN_Een << NVMC_CONFIG_WEN_Pos);
What is the reason for this? It doesn't appear to be a timing issue because the flash was not yet being erased. Just accessing the CONFIG register in the NRF_NVMC is sufficient to cause the program to stop.
How can I get around this issue as I need to be able to access about 32K bytes of flash space contiguously and the "Flash Manager" that comes with the mesh stack doesn't seem to be suitable for my purpose.
Thank you very much for any help.


