
I’m experiencing random connection failure when transferring data (both ways at the same time) between my peripheral (Slave) and central (Master) device.
The problem appeared just after upgrade to the SoftDevice 132 (version 6.0) and SDK (version 15).
There was no such issues with previous versions of SoftDevice (5.0) and SDK (14).
The problem occurs when 2 devices (Master and Slave) starts to stream data bi-directionally with a speed of about 8 kB/second each.
It takes from few seconds up to few minutes when connection fails and both devices starts to report an error (NRF_ERROR_RESOURCES) at the same time.
Furthermore, once this situation happen, the connection on master device seems to be dead completely.
The device is not capable to send/receive notifications anymore (using different characteristic) and is not "aware" of any connections events.
For example, the Slave device can be powered-off and the Master device does not receive “disconnection” event.
There is no issues with connection, pairing or bonding.
Sending notifications, indications or small amounts of data from one device to another seems to be ok too.
The problem starts when devices goes into fast “streaming mode” and larger amounts of data are exchanged.
Both devices are based on nrf52382 and using latest SoftDevice 6.0/SDK 15.
Slave device uses “interrupt dispatch model” (NRF_SDH_DISPATCH_MODEL_INTERRUPT).
Master device uses RTOS and “polling dispatch model” (NRF_SDH_DISPATCH_MODEL_POLLING)
Both devices uses custom Services which are very similar to the “ble_nus” and “ble_nus_c” from the SDK.
Functions used for sending data are: sd_ble_gatts_hvx and sd_ble_gattc_write.
Connection parameters (including negotiated ones) are as follows:
Data length 251 bytes
ATT MTU 247 bytes
PHY set to 2 Mbps
MIN_CONNECTION_INTERVAL 10 ms
MAX_CONNECTION_INTERVAL 20 ms
SLAVE_LATENCY 0
SUPERVISION_TIMEOUT 4000ms
NRF_SDH_BLE_GATT_MAX_MTU_SIZE 247
NRF_SDH_BLE_GATTS_ATTR_TAB_SIZE 1408
NRF_SDH_BLE_GAP_EVENT_LENGTH 400
An observation has been made (but not 100% confirmed):
When sending data in packages by 244 bytes (247-3) the connection seems to be stable.
Occasionally, “NRF_ERROR_RESOURCES” errors appears and this is normal (I know I need to wait for the BLE_GATTS_EVT_HVN_TX_COMPLETE / BLE_GATTC_EVT_WRITE_CMD_TX_COMPLETE events) but connection stays alive for long time.
When data is sent in smaller “packages” (by 160 bytes) the connection fails usually after few seconds.
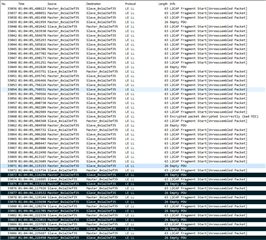
I’ve tried to use nRF Sniffer to catch the moment when connection fails.
It wasn’t easy, as the tool is not upgraded and has many limitations. However, few screenshots has been made.
First picture shows the moment when Master device stops to respond (pos no. 33071).
Other pictures shows very last packets that has been sent over.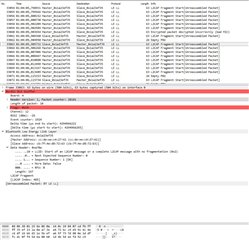
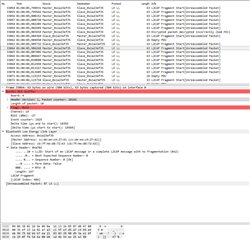
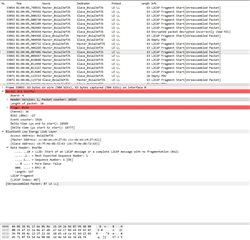
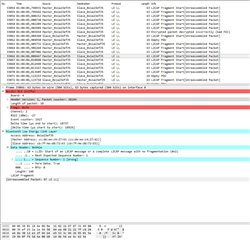
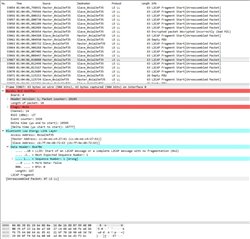
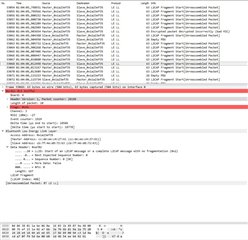
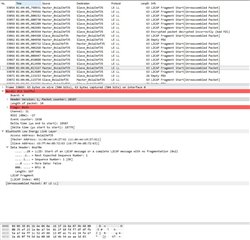
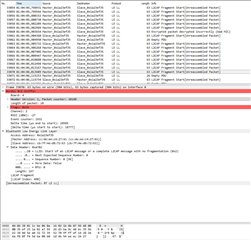
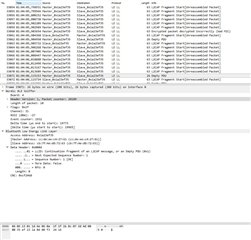
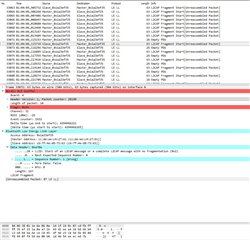
I’ve spent few days to investigate the problem in BLE parameters, memory leaks, RTOS tasks and priorities, stack sizes and in many other places.
Please give a hint for the solution.
PS: The solution isn’t the downgrade to the SoftDevice 132 (version 5.0) and SDK (version 14) as those version has other pairing/bonding issues with latest Android devices.


