My application needs to keep time and support local time as well. I have implemented a service that allows setting the epoch seconds as well as a local timezone string. With these two items, I can update the epoch seconds and determine local using the Clib time.h functions (e.g., localtime(), ctime(), etc.). In order for these time functions to work correctly, I call
setenv("TZ", timezone_string, 1);
to set the local timezone parameters. This works fine when I call setenv() from a CLI command, however when I call it in response to my change timezone characteristic (in the BLE event handler, BLE_GATTS_EVT_WRITE event), I get a hardfault in the Softdevice, at address 0x13624. Here are some details of my environment:
- nRF52832 with SDK 14.2
- Softdevice S132 5.0.0
- Eclipse IDE with gcc 7.2.1 (gcc-arm-non-eabi-7-2017-q4-major)
- My app is uses FreeRTOS
- FreeRTOS uses heap_4.c with ucHeap[] statically allocated in BSS and NOT as part of normal HEAP section
- HEAP section set at 1kB - for setenv() and other Clib functions
- No corruption observed in HEAP or in C environment area used by setenv() (i.e., after a call to sentenv(), heap contains correct string "TZ=MST7MDT" whether called from CLI or BLE interface)
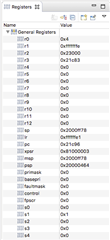
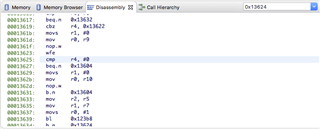
I've attached a screen shot of the CPU registers at the time of the hardfault and disassembly of the location of the hardfault in the SD.
If someone could shed some light on this issue, that would be greatly appreciated!