
Hello,
When debugging one of the projects, I encountered the situation of a frequent reset of the device during connection. A quick scan under the debugger helped show the cause: a hard failure.
More detailed debugging helped identify the following points:
- Error occurs only in the state of connection. This is reasonable, since only in the state of the connection processes of receiving, processing and transmitting data are started;
- The error does not depend on the degree of filling the stacks. The stacks were filled with a pattern using a macro. Analysis of the contents of the stack after the error shows that it can be either overflowed or free by 2/3;
- The RTOS task stacks are allocated with a surplus. Reducing / increasing the size does not affect the frequency of the error;
- The project uses several objects of the nrf_queue. If an error occurs, the contents of the field control structure (p_cb) of one or more objects has an invalid value. This fact allowed the use of an additional breakpoint (I signed color variables whose addresses are used to stop):

The breakpoint data helped to detect that an error occurs at the moment of switching the context of the RTOS in the interrupt vector - xPortPendSVHandler. The "watch" windows use for control values:
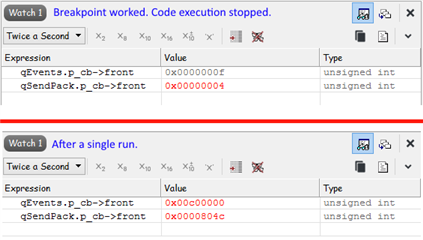
Also, the data values in the buffers are corrupted. At first glance, this data is similar to the contents of the stack, but I'm not so sure.
If you do not use breakpoints, then when a hard failure occurs, the output to the log is as follows:
HARD FAULT at 0x00000000 R0: 0x20000464 R1: 0x00000000 R2: 0x00000000 R3: 0x20014D30 R12: 0xFFFFFFFF LR: 0x00000000 PSR: 0x4000000E Cause: The processor has attempted to execute an instruction that makes illegal use of the EPSR.
Disassembly window with 0x20014D30:
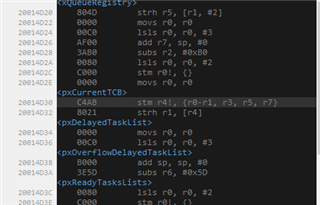
The value R0 = 0x20000464 is in the stack address space.
So, at the moment I see the result in the form of a falling program and the reason in the form of an error when switching context. But I can not understand why this error occurs.
1. If I understand correctly, the queue module is used within itself by critical sections for write / read operations. How safe is it to use these functions as part of a RTOS?
2. Maybe there is a possibility of a simultaneous occurrence of a write event to the nrf_queue and a context switch? But so far I have no idea how to catch it.
Below I give a list of interrupts involved by me. Priority for them, I use the default.
Used:
HW: Fanstel BT840 (nrf52840);
FW: SDK 15.3.0, project based on "ble_app_hrs_freertos". In project added: nrf_queue module.
List of interupt:
GPIOTE->EVENTS_IN (~250 Hz);
TWIM1_EVENT_ERROR / EVENT_STOPPED (~250 Гц)
NRF_TIMER4->CC (10Hz);
TWIM0_EVENT_ERROR / EVENT_STOPPED (10 Гц)
SW: Segger Embedded studio 4.18


