
We're seeing an issue where the soft device stops responding and ultimately disconnects with the reason BLE_HCI_INSTANT_PASSED. The disconnection only seems to happen when a LL_CHANNEL_MAP_REQ message is received while the Nordic is performing a flash erase. The Wireshark capture from a sniffer shows the master is resending the LL_CHANNEL_MAP_REQ, but the slave doesn't send a response until after the instant has passed, triggering the BLE_HCI_INSTANT_PASSED disconnection.
During the time when the flash erase is happening, we've captured instances with and without the channel map update request. Without the request, the device also stops responding, but eventually recovers:
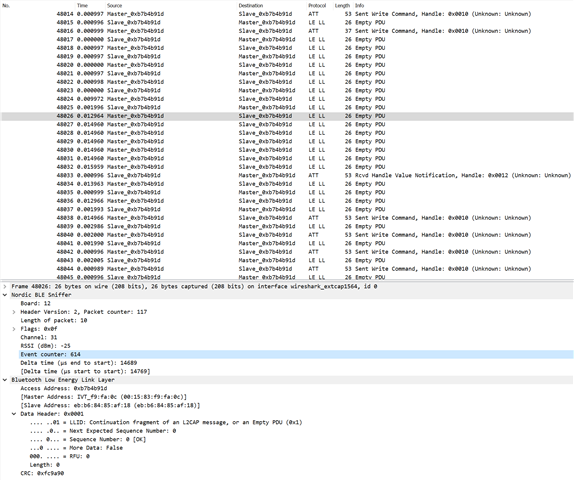
If the slave receives a LL_CHANNEL_MAP_REQ message during the erase, it misses the instant and disconnects:
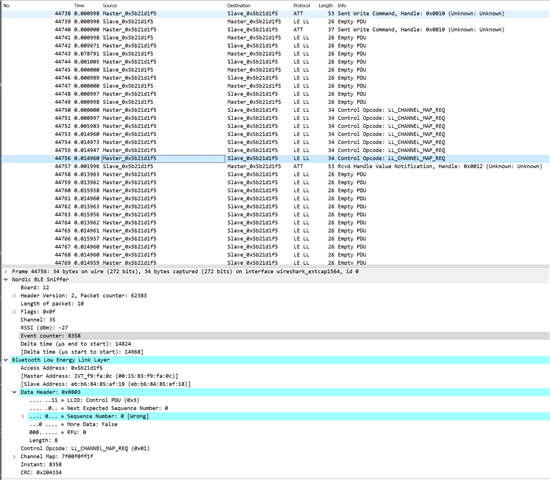
We're using Soft Device S140 Version 6.1.1.
Is there any reason why the slave would stop responding during the flash erase if we're using the soft device flash API? What determines how far into the future the instant is calculated during a channel map update? Is there any other explanation for this behavior?
Thanks!



