Hi,
I'm using nrf52840, Segger 4.52c, Windows 10. Light Switch Mesh Example. Mesh SDK 4.1 NRF5 SDK 16 Softdevice 7.0.1
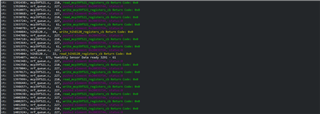
I successfully added TWI communication to this example and I am reading the MCP39F521 TWI device. It works great but I recently added a humidity sensor to the mix and implemented nrf_twi_mngr class once I saw where the two devices would stop reading after a while. The problem is that even though the manager schedules the TWI transmissions, I still have an error occurring whenever the humidity sensor starts a read cycle.
So here is a bit of information on the TWI devices: The Humidity sensor requires 40ms to complete a calculation cycle after ith gets the command to do so. Therefore I have a app_timer which sends the measurement request, waits 40ms, then sends the read request and waits 1 second before doing it again. The MCP39F521 is being polled every 20ms for a voltage reading. I have to write the command to it, wait 10-15ms and then read the data from it.
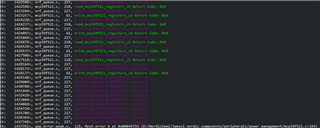
The error usually occurs when the humidity sensor asks for a measurement request. The TWI manager callbacks stop coming in and the buffer fills up and throws a NRF_ERROR_NO_MEM error. I can't figure out why the callbacks stop firing.
Can anyone point me in the right direction?