Hi Team,
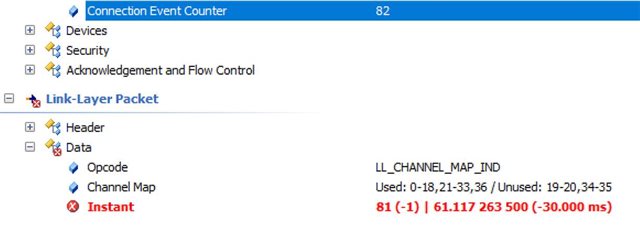
We are seeing an intermittent issue where BLE connection disconnects abruptly due to reason BLE_HCI_INSTANT_PASSED (0x28). We are using nRF SDK version 15.2.0. The mobile device is Moto G7 Power which runs on Android OS. We have seen this issue 8 times in past month with the same device. Please help us with the following queries:
1. When can this happen? I have seen a stack overflow post explaining the possible reasons. Is that an exhaustive explanation?
2. How can we prevent it? Our customers can have multiple types of devices hence we are looking at a firmware level solution. We came across this link to extend connection event length. Can that help?
Thanks in advance