Hello,
In a quite particular configuration, the nRF8001 sometimes stops responding. The only way to make it work again is to do a hardware reset using the reset pin of the transceiver. Is there a workaround to prevent the freezing?
HW-Setup: MSP430 as a master device on the SPI bus. nRF8001 module by Insight SIP (ISP091201)
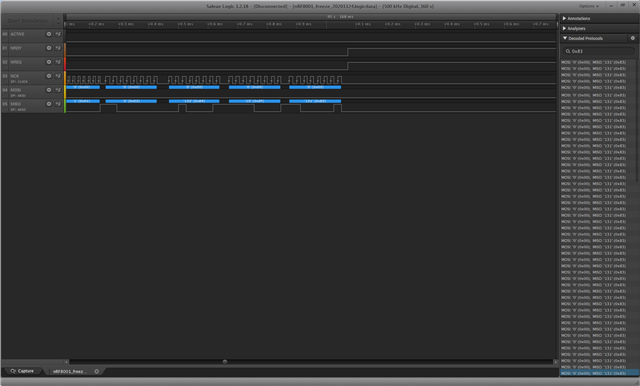
How to reproduce the problem: Using the HID setup of our device, we pair with a mobile phone (e.g. iPhone SE (2018), iOS 14.1). Then a new setup for unpaired connections without security is loaded. The new setup contains several proprietary services that are completely different from the previous HID service. Seeing the same MAC address, the phone tries to restore the connection with our device but disconnects after about seven connection intervals. The MSP430 reads the dynamic data and restarts the advertising for a new connection (still without pairing). The phone recognizes the address and connects again... After some iterations of this process, there is no more connection (active signal not available anymore) and the nRF8001 becomes unresponsive. It doesn't accept new commands anymore. When pulling nREQUEST line to zero, the nRF8001 will not pull the nREADY line to zero. The last successful command is a connect-command that is confirmed by a command response event (without error) sent by the nRF8001.
I will attach a compressed trace of the Saleae logic analyzer containing all relevant signals7450.nRF8001_freeze_20201124.zip
A simple solution is to delete the bonding information of the phone which then stops its connection attempts. This works, but the goal is to have a foolproof device with the nRF8001. Did we miss out on something? Any suggestions?
Best regards
David

 PAN025 Product Anomaly Notification v1.5.
PAN025 Product Anomaly Notification v1.5.