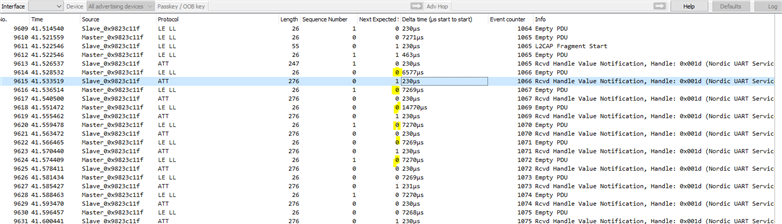
I have a sensor which I'm grabbing FIFO data from every 14msec, ~240bytes. I send these FIFO grabs as soon as they arrive.
My connection parameters:
Connection Interval: 10msec
MTU = 247
DL=251
hvn_tx_queue_size = 36
event_length = tried 8 ~ 18
PHY = tested both 1Mbps and 2Mbps
According to the timing, the FIFO data grabs occur every 14msec, so under the Connection interval. Therefore the Buffers should never fill up. However after about 200 data sends I get the NRF_ERROR_RESOURCES error. Is there a setting I'm missing, why would the Radio be throttling? If the MTU is 247 and Interval 10msec, assuming single packet in a Connection Event it should support up to 24kB/sec (with 240byte payloads). According to the FIFO data grab date it only needs ~17.2kB/sec. So where am I missing something that would cause the link not to be able to support the Data Rate and hit Buffer FULL errors? I do handle this by wait on the BLE_GATTS_EVT_HVN_TX_COMPLETE but I don't want to lose any incoming data.
I'm currently using an nRF52840, SDK 16, S140 v7.0.1
Thanks for the help guys,
DC