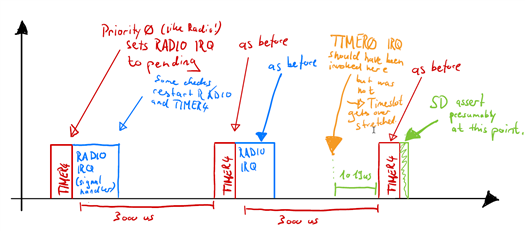
I'm trying to narrow down the cause of a Softdevice assertion happening in S132 7.2.0 at PC=0x15810.
We set up a proprietary RF project which utilises parts of the SDK for Mesh (specifically, the timeslot implementation and bearer_handler) because it provides a safe base to run high performance timeslot applications on. Unfortunately I do have one device which runs into a softdevice assertion at instruction 0x15810. I feel that it is a timing issue - maybe the device is operating at the outer limits of the clock accuracy, because while the issue appears sporadically on Development Kits or other devices, this specific device does trigger it quite often.
- What exact assertion fails when at PC=0x15810?
- Does the Softdevice shut down TIMER0 before doing this test or after an assertion fails?
- Are timing assertions made by the softdevice based on RTC0?
- Is there a reason why TIMER0 in the mesh stack is running in 24-bit mode as opposed to 32-bit mode?
Any help is greatly appreciated.
EDIT: In the meantime I think I found the cause of the issue. Assuming that the timing assertions by the Softdevice are done using RTC0, there seems to be a rather large discrepancy between the RTC0 timing and TIMER0 timing. After 9'999'249us on TIMER0 pass, RTC0 has counted 10'000'732us, so they're almost 1ms apart!
The device in question is running the LFCLK from the RC oscillator and we do usually have BLE deactivated. I did assume that the softdevice takes care of adjusting for clock drift, but could it be that I have to somehow take care of this manually?
EDIT2: Note that - as we're using the nRF SDK for Mesh as a codebase - when calculating the available time on the timeslot, we should already account for clock drift per the following calculation:
(p_timeslot->length_us * (m_lfclk_ppm + HFCLOCK_PPM_WORST_CASE)) / 1000000;
EDIT3: I previously wrote that we "do usually have BLE deactivated". What I actually mean by this is that most of the time the device is neither connected nor is it currently advertising. So there is no BLE activity to schedule by the softdevice. Timeslots are always active, though.