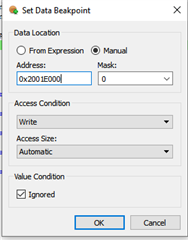
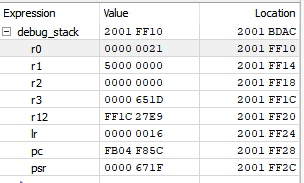
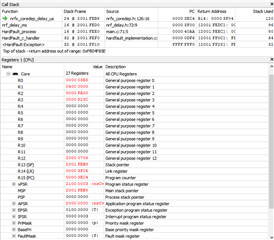
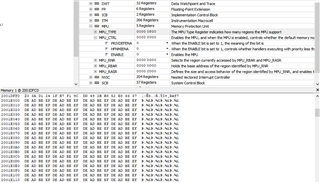
I have a bit of an odd one, and would appreciate any input. We have a fairly complex project, which does various things, but some of the time, I get a hardfault. The issue appears to be a instruction access violation (MMFSR->IACCVIOL = 1). Working backwards, the code that caused this seems to be the nrfx_coredep_delay_us function (in nrfx_coredep.h).
We're using the 17.0.2 SDK, and the code in question is this, and the PC points to delay_machine_code:
__ALIGN(16)
static const uint16_t delay_machine_code[] = {
0x3800 + NRFX_COREDEP_DELAY_US_LOOP_CYCLES, // SUBS r0, #loop_cycles
0xd8fd, // BHI .-2
0x4770 // BX LR
};
typedef void (* delay_func_t)(uint32_t);
const delay_func_t delay_cycles =
// Set LSB to 1 to execute the code in the Thumb mode.
(delay_func_t)((((uint32_t)delay_machine_code) | 1));
uint32_t cycles = time_us * NRFX_DELAY_CPU_FREQ_MHZ;
delay_cycles(cycles);
I wasn't entirely sure about the way the code is hand-loaded in, so I tried switching to using the DWT instead (since the 53833 supports that). This produced the same hardfault behaviour, only now it's on
while ((DWT->CYCCNT - cyccnt_initial) < time_cycles)
{}
I suspect there's something else going on here. Our code does use nrf_delay_ms for certain things that need busy waits, which calls through to the above code, but it only hardfaults some of the time. As above, we're using SDK 17.0.2, nrf52833 on a custom board.
I'm at a bit of a loss on this one, suggestions welcome?