To the kind attention of Nordic support team,
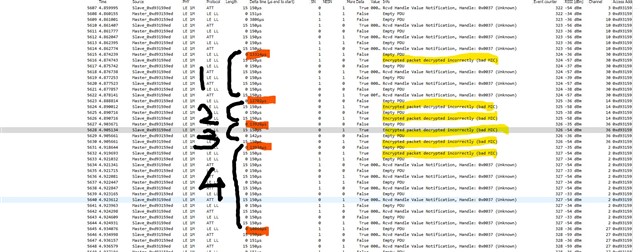
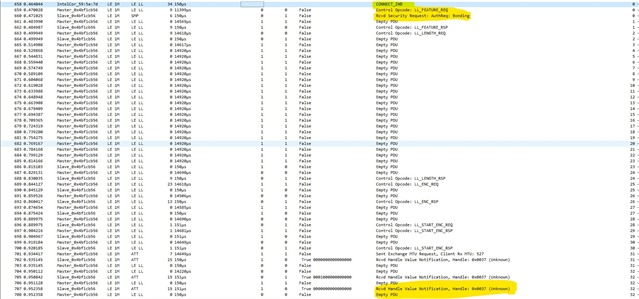
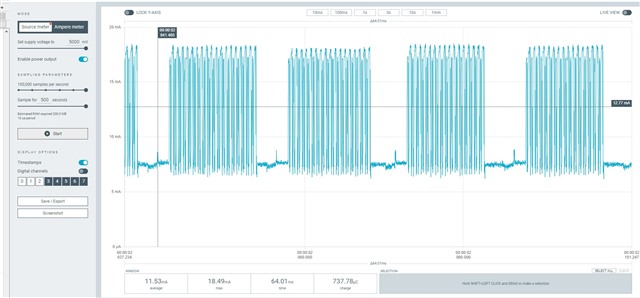
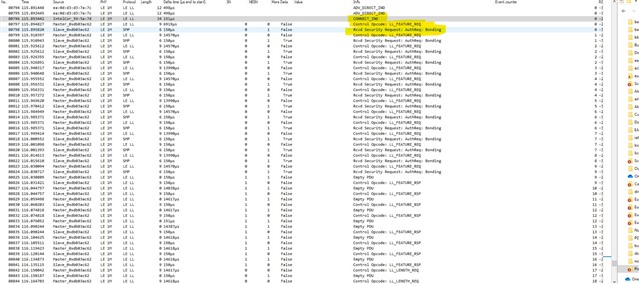
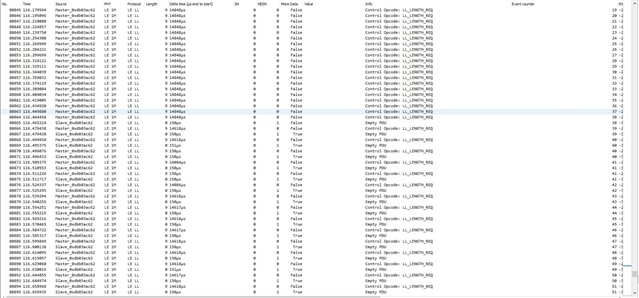
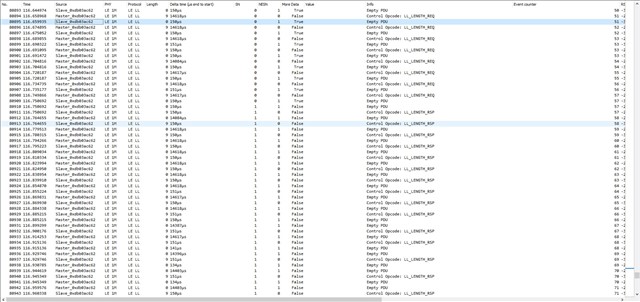
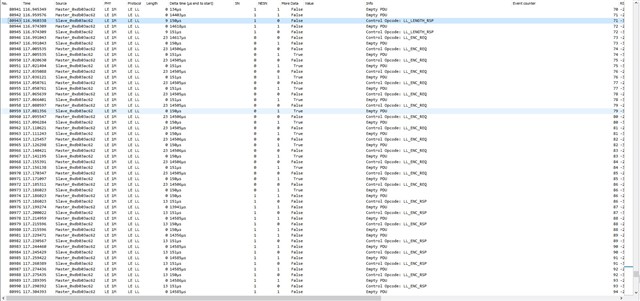
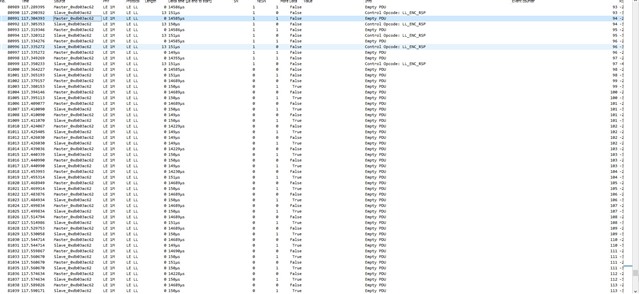
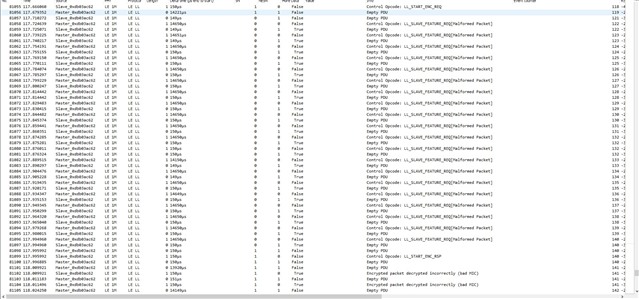
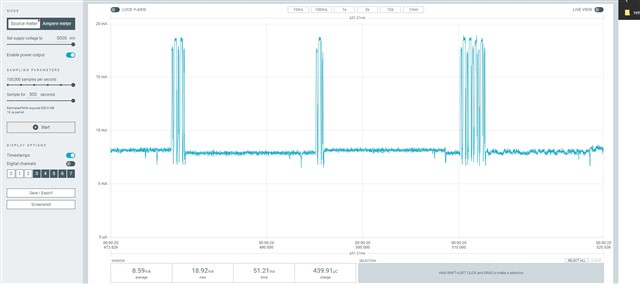
I'm testing a freertos project, with softdevice and radio notifications. A constant number of notifications is queued before the starting of the connection interval, and sent during the connection interval itself. It works very well, I get this high speed data stream. Every time I get a sporadic NRF_ERROR_RESOURCES, the feedback mechanism exploiting BLE_GATTS_EVT_HVN_TX_COMPLETE starts working as well, and the resource error disappear after a while.
Everything works fine, like 9 executions of the program out of 10 are really stable and NRF_ERROR_RESOURCES free. If I reset (Ctrl+Shift+F5 using Segger), it seems that, once in a while, from the beginning of the connection NRF_ERROR_RESOURCES is massively there, and it never goes away. Only reducing the number of queued notifications help.
But why the number of notifications should be reduced once in a while? All this sounds to you like a problem in the application, or there could be something changing in the connection? I thought about master forcing a different connection interval than the desired one. But using BLE_GAP_EVT_CONN_PARAM_UPDATE_REQUEST I have no evidence for now that this behavior is due to a change in connection interval timing. I attached systemview files to the project and next days I'll be possibly able to post some more thing about this issue (also I'm gonna use Nordic sniffer). Really, just a quick opinion from your experts would be very much appreciated. Also, any debug strategy you would recommend.
Thank you in advance, best regards.