Hello everyone.
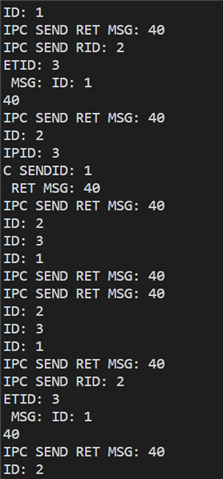
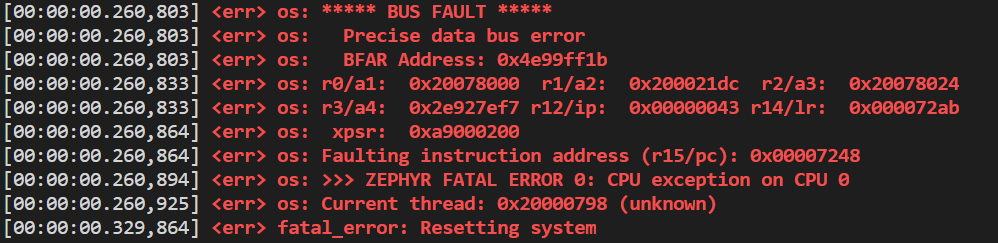
I was trying to integrate the ipc_service sample in my application. It was working all fine and I was able to set up and link the endpoint in my code. I then tried to run a clean build, and I don't know why everything broke: when I try to execute ipc_service_register_endpoint, this happens, the board resets and keeps doing it forever.
Thinking that is a matter of memory position, I found out that my compiled devicetree output for the application core has a reserved-memory node like this
reserved-memory {
#address-cells = <1>;
#size-cells = <1>;
ranges;
sram0_image: image@20000000 {
reg = <0x20000000 DT_SIZE_K(448)>;
};
sram0_s: image_s@20000000 {
reg = <0x20000000 0x40000>;
};
sram0_ns: image_ns@20040000 {
reg = <0x20040000 0x30000>;
};
sram_rx: memory@20078000 {
reg = <0x20078000 0x8000>;
};
};
Instead of
reserved-memory {
sram_tx: memory@20070000 {
reg = <0x20070000 0x8000>;
};
sram_rx: memory@20078000 {
reg = <0x20078000 0x8000>;
};
};
Network core side instead, the devicetree seems ok, but I still encounter the error at endpoint registration time.
I am quite lost and I don't really know how to proceed, since this problem appeared point-blank when I tried to build from zero once again.