Hello,
I am working on a project with the MPSL timeslots. There I am using the radio, and at certain radio interrupts I want to send data to another thread. For this purpose I want to use a message queue.
However, something is not working correctly, as the program typically freezes after a few minutes, sometimes even after a few seconds.
I created a simpler version of my project based on the timeslot example where I also managed to reproduce this problem. I left out the radio activity part and I am now just sending several messages in the case of MPSL_TIMESLOT_SIGNAL_START.
The message queue is defined as following:
K_MSGQ_DEFINE(data_msgq, 1, 120, 1);
In the case of MPSL_TIMESLOT_SIGNAL_START I am sending several messages. (In my actual program I would just send one data item, but the interrupt itself would happen several times within one timeslot. But this seems to produce the same problem.)
static uint8_t test_val = 0;
for(int count = 0; count < 20; count ++)
{
test_val++;
k_msgq_put(&data_msgq, &test_val, K_NO_WAIT);
}
Another thread periodically tries to request the next earliest timeslot and then (after some sleep) tries to read all available data from the queue (with a maximum allowed limit to read):
uint8_t data_recv;
uint8_t max_data_count = 0;
do {
if(k_msgq_get(&data_msgq, &data_recv, K_NO_WAIT) != 0)
{
break;
}
LOG_INF("%d", data_recv);
max_data_count++;
if(max_data_count == 40)
{
break;
}
}while(1);
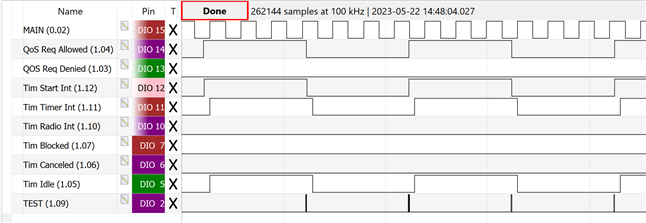
As already stated, the problem is, that after some time the program completely freezes, no more log messages are printed. I also added several GPIO outputs for testing. Everything stops, even the separate main thread that just would toggle a GPIO output every 15 ms is not executed anymore.
void main(void)
{
while(1)
{
gpio_pin_toggle_dt(&gpio_main);
k_sleep(K_MSEC(15));
}
}
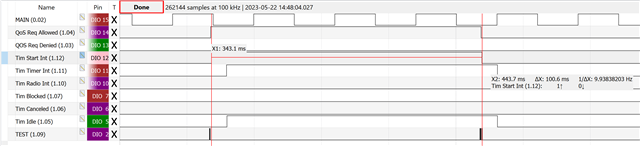
From the measurements it seems that the freeze happens within MPSL_TIMESLOT_SIGNAL_START where it appears to stop when trying to add an element to the message queue, where it halts and then never finishes the interrupt routine. But from the implementation it should not be possible to wait there (K_NO_WAIT), something else would even be not allowed as it is running in the context of the TIMER0 interrupt.
When setting the log mode to CONFIG_LOG_MODE_DEFERRED it now did not just freeze, but I also had an assert message printed before an automatic reboot, which names a recursive spinlock as the issue. I have already gotten such spinlock asserts when trying out other things with the MPSL timeslots. I never investigated this in detail, but it seems that this happened when doing much logging within the interrupts itself or scheduling several work queue tasks within the Interrupts, which I am both not doing in this example. But maybe the current issue is still somehow related.
00> ASSERTION FAIL [z_spin_lock_valid(l)] @ WEST_TOPDIR/zephyr/include/zephyr/spinlock.h:148 00> Recursive spinlock 0x200012dc 00> [00:01:04.149,536] <err> os: ***** HARD FAULT ***** 00> [00:01:04.149,902] <err> os: Fault escalation (see below) 00> [00:01:04.150,299] <err> os: ARCH_EXCEPT with reason 4 00> 00> [00:01:04.150,695] <err> os: r0/a1: 0x00000004 r1/a2: 0x00000094 r2/a3: 0x00000000 00> [00:01:04.151,214] <err> os: r3/a4: 0x20000bac r12/ip: 0x00000000 r14/lr: 0x0000ae8d 00> [00:01:04.151,733] <err> os: xpsr: 0x41000018 00> [00:01:04.152,130] <err> os: Faulting instruction address (r15/pc): 0x0000c164 00> [00:01:04.152,587] <err> os: >>> ZEPHYR FATAL ERROR 4: Kernel panic on CPU 0 00> [00:01:04.153,076] <err> os: Fault during interrupt handling 00> 00> [00:01:04.153,442] <err> os: Current thread: 0x20000a20 (main) 00> [00:01:04.163,879] <err> fatal_error: Resetting system
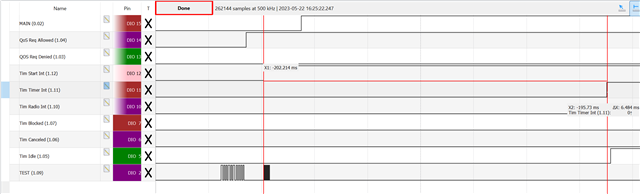
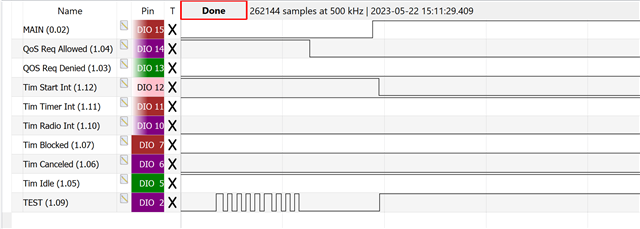
The error is more consistently to reproduce, when always less messages are read from the queue than put into it. So the queue slowly fills up. Also sending more messages and reducing the timeslot duration increases the chances of getting an error early.
The weird thing is, that the logging seems to have an impact. Because, when disabling the logging completely I at least could not see an error occurring according to the GPIO traces.
But it cannot be the logging alone that causes the problems. When not using the message queue, but just storing the data in a global array from which the other thread reads the data, also no problems arise, even with the same amount of log output.
Any ideas what might be causing the problems?
In case it helps, here a link to the project on GitHub.