System Details:
Chipset: nRF52840
SDK: nRF52 SDK v17.0.2
Using Zephyr: No
Overview:
The documentation for FDS has been very helpful, and with that, I was able to get something running pretty quickly, but I would like to ask a couple of questions regarding FDS files and records.
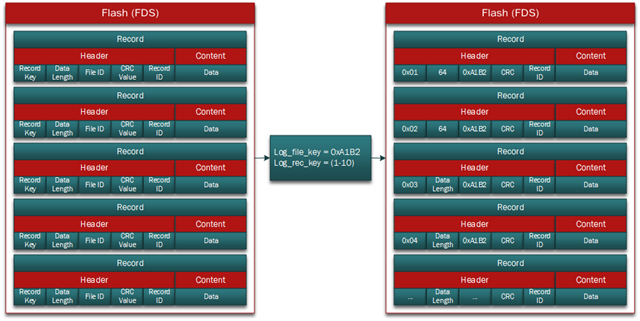
As part of a logger design, I want to track the number of resets. Nordic actually has an example of precisely that type of functionality. Basically, they open the record, update the boot count, close the record, and perform the update. This works as expected, but my question is mainly about organizing FDS files and FDS records to get the most out of the design.
Questions:
As part of the logger I mentioned above, I want to write logs to Flash and track the resets. However, I don’t want to marry the two entities. Instead, I would like them to be separate files. As such, I was thinking of having one file to track all my logs, and one file to track the reset counts. That way I can query just the boot count, without having to search through all the logs, as they live in different files.
With that said, my questions are pretty basic:
- Is there a way to specify how many pages per file? For example, say I wanted to reserve 4K for logs, and 1K for the reset count, each of which would be separate files, with multiple records.
- Does my logic above make sense, where you would use one file for (n) number of records, or in my case, logs? If so, is there a maximum number of records per file? Or any sort of rollover that is required?
- This could certainly be a misunderstanding on my end, but I noticed that the examples hardcoded the record key. For example:
static void ndef_file_prepare_record(uint8_t const * p_buff, uint32_t size) { // Set up record. m_record.file_id = FILE_ID; m_record.key = REC_KEY; m_record.data.p_data = p_buff; m_record.data.length_words = BYTES_TO_WORDS(size); // Align data length to 4 bytes. }
In my case, I thought each log would have its own record key to prevent overwriting the last entry, but maybe that's not how it works. I'm just thinking of the case where you have a single file, which contains 100 logs. I thought each log would be considered a record, so I hoped not to specify the key.