Hi,
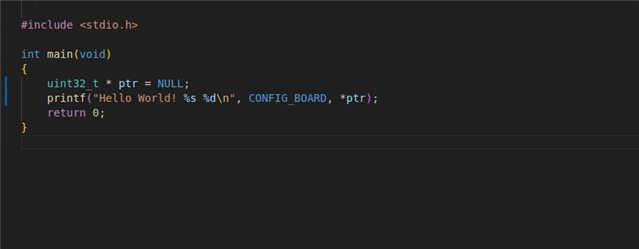
I'm developing an application on the nRF9160DK with custom firmware for both the nRF52840 as well as the nRF9160 on the board, using VSCode with the nRF Connect extension. (I'm currently on ncs v2.5.0 in case that matters.) Development is mostly going well, but I recently started running into the nRF9160 soft resetting (reset reason: 65536) which I'm not sure how to debug since there is nothing being logged which could point me to what is going wrong. Could you provide me with any pointers on how to go about debugging soft resets of the nRF9160?
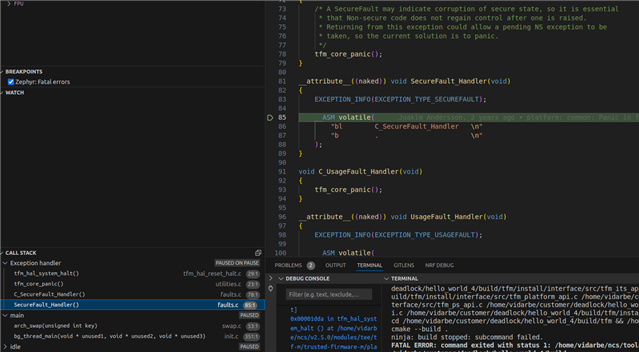
With hard faults I could set the debugger to set a breakpoint whenever a "Zephyr: Fatal error" occurs, but this is not the case here since it's only a soft reset and not a hard fault. Is there a way to generate hard faults whenever a soft reset happens?
Best,
Wout