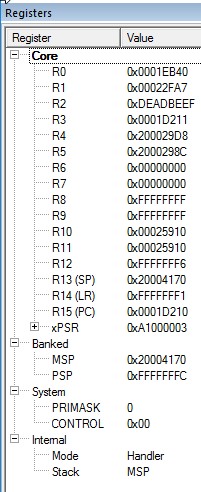
My app is generating hardfualts. Based on this post I looked at memory location SP + 0x14, which points to the address that generated the fault.
Memory at SP+0x14: 8F 31 02 00, which is address 0x0002318F. Which points to:
void on_tx_complete(const ble_evt_t * event)
{
uint32_t err = 0;
if(event == NULL)
err = 0xFF;
APP_ERROR_CHECK(err);
tx_buffer_process();
}
The if(event == NULL) was my fatal attempt to catch the error. I had a breakpoint on err = 0xFF; that never triggered.
Using Keil's dissassembly window I see the following:
407: tx_buffer_process();
0x0002318A F001FFBD BL.W tx_buffer_process (0x00025108)
408: }
0x0002318E BD70 POP {r4-r6,pc}
0x00023190 2E2E DCW 0x2E2E
0x00023192 2E5C DCW 0x2E5C
0x00023194 5C2E DCW 0x5C2E
0x00023196 2E2E DCW 0x2E2E
0x00023198 725C DCW 0x725C
0x0002319A 6D65 DCW 0x6D65
0x0002319C 746F DCW 0x746F
0x0002319E 2E65 DCW 0x2E65
0x000231A0 0063 DCW 0x0063
0x000231A2 0000 DCW 0x0000
I believe POP is loading the PC with a bad value. Is there some way I can check R4 - R7 for valid values before calling on_tx_complete()?
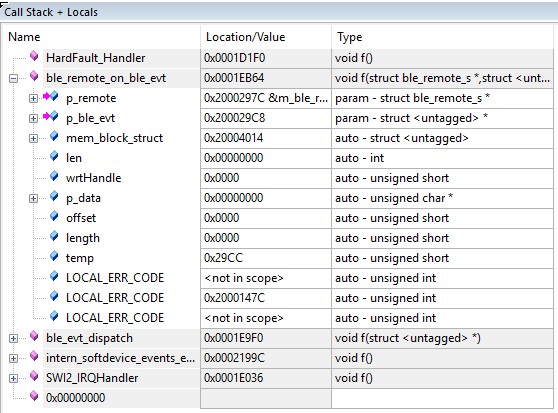
I can trace the call to on_tx_complete() back ble_remote_on_ble_evt(), and a BLE_EVT_TX_COMPLETE event. I don't know where to go from here. on_tx_complete() executes multiple times before the hardfualt, and the hardfualt seems to happen at random. What would have caused the hardfault? What else should I be looking at?
The call stack, when the fault occurred looked like:
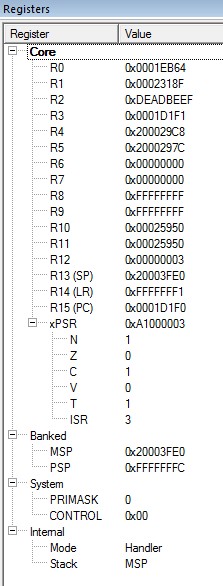
My registers have:
Thanks