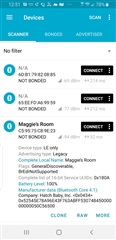
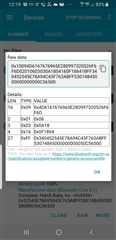
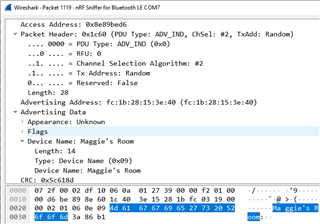
I have a BLE device for which the local name contains and apostrophe. When I run nRF Connect on an Android phone and view the raw data for this device I find the apostrophe is represented by the following three hex bytes: 0x80 0x99 0x73. I am developing an App that reads the local name and I find the same 3 bytes for this device at the location of the apostrophe in the scan report data. I am curious as to how you came to interpret these 3 bytes as an apostrophe when that is usually represented by the single Ascii byte 0x27?