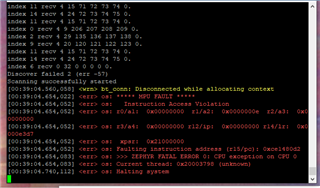
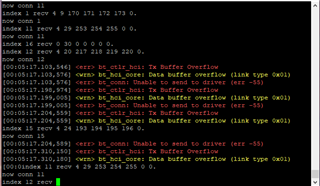
Recently I am using BLE in Zephyr to implement the multilink central function
However, none of the references currently have a similar function, and there is also the nordic zephyr code
https://github.com/nrfconnect/sdk-nrf <-There are only examples of multilink peripherals in this link
So I wrote one to implement it. The goal I want to achieve is one central to 30 peripherals
The current connection with 4 peripherals is fully stable, but when I increase the connected peripherals, the following error will appear
<err> bt_attLATT Timeout <wrn> bt_att: No ATT channel for MTU 5 <wrn> bt_att: No pending ATT request
The picture below shows the error when connecting 20 peripherals
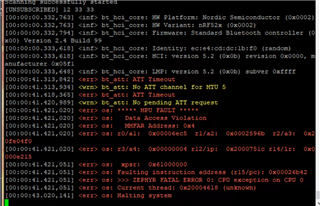
At present, I know that modifying the Interval connection will indeed improve, but only to make <err> bt_attLATT Timeout happen later.
How can I avoid this problem so that I can connect 30 peripherals stably?
Below is my code
Or you can go to this page to download https://github.com/mfinmuch/zephyr-ble-mulrilink-test
Thanks,
Poyi