Hello,
I want to read a status register in my SPI peripheral. Once I send my read request, the peripheral will send the status byte over and over, and I want to watch for a change. When it changes, I want to terminate the SPI transfer.
What is the best way to do this? The complication here is that there isn't a fixed RX buffer length. The status byte might change in 5 bytes or 100 or 1000. It seems suboptimal to allocate memory for a really long transfer buffer just to accommodate, say, the case in which it takes 1000 bytes for the status byte to change, both because of the extra memory, and also because there's no way to know if it'll even be enough. I am using this function:
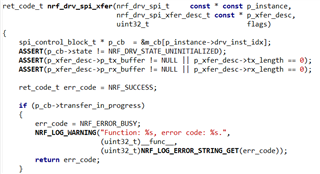
ret_code_t nrf_drv_spi_transfer(nrf_drv_spi_t const * const p_instance, uint8_t const * p_tx_buffer, uint8_t tx_buffer_length, uint8_t * p_rx_buffer, uint8_t rx_buffer_length)
Is there a way I can push the RX bytes into a queue, maybe, pop from the queue to read the bytes (which makes room for more bytes to be clocked in on SPI), then abort the spi transfer when I notice the changed byte? If so, is there a way to make sure the dequeueing rate is faster than the spi transfer rate? Or can I read from the transfer buffer even if it is not full?
As a workaround, I guess I could TX my read request over and over and get back a few status bytes each time (buffer length = n+1, TX length = 1, RX = n), but it seems like this would defeat the purpose of SPI.
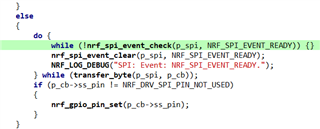
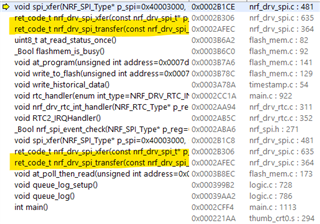
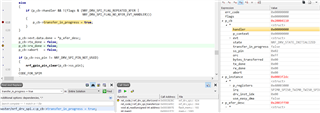
Note: I think, based on the below screenshot, that I am using SPI and not SPIM.
Thanks!