Hi,
I am toggling a GPIO using the below code and trying to find out the relation of the frequency and the code statements. I know that GPIO peripheral is running at 16MHz and I have added the 'nop' instructions to make sure that the changes take effect before I change the pin state again.
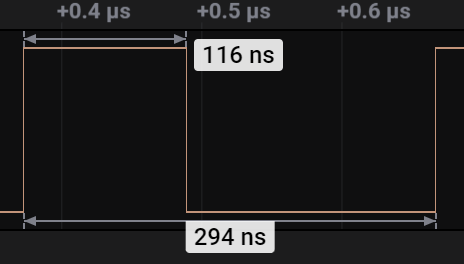
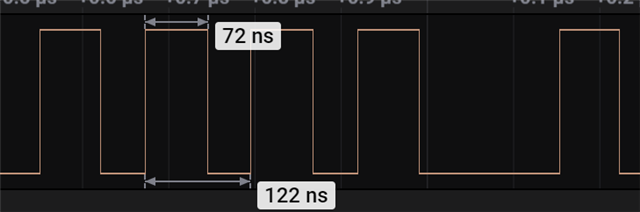
1) How can we relate '116 ns' and '294 ns' from the below code. I understand that each nop takes 1/(64*10^6) second.
2) I read in the forum that 8 MHz is the maximum frequency which can be achieved on a GPIO even though it has 16 MHz. Why is it so ?
C code:
while(1) { NRF_P0->OUTSET = 0x04000000; __NOP(); __NOP(); __NOP(); __NOP(); NRF_P0->OUTCLR = 0x04000000; __NOP(); __NOP(); __NOP(); __NOP(); }
Equivalent Disassembly:
NRF_P0->OUTSET = 0x04000000; F8C32508 str.w r2, [r3, #0x0508]__NOP(); BF00 nop__NOP(); BF00 nop__NOP(); BF00 nop__NOP(); BF00 nopNRF_P0->OUTCLR = 0x04000000; F8C3250C str.w r2, [r3, #0x050C]__NOP(); BF00 nop__NOP(); BF00 nop__NOP(); BF00 nop__NOP(); BF00 nopwhile(1) E7F2 b 0x0001AECA