
I'm experiencing a strange issue that I can't seem to figure out. We've built a location system based around the nrf52833, and we're currently running this system in a pilot installation at a customer site. Tags (consisting of a nrf52833, a LIS3DH accelerometer--which is disabled, and a CR2477 battery) are mounted on short flags with strong magnetic bases--the tags are mounted about 8" or so from the magnets. The flags are stuck to/pulled from heavy equipment moving around a very large shop floor. In addition to location, the tags periodically uplink their battery voltage. What we've found is that every once in a while, a tag will enter an anomalous state in which it suddenly begins to draw a constant high current (as evidenced by the battery voltage), and dies within 10 days or so. I'd estimate the current to be around 3mA, which is consistent with the processor not entering its low power idle state. However--and here's the part that's confounding me--we can remotely reset these tags, and doing so does NOT cause the behavior to go away. The only way to 'fix' the issue is to physically remove the battery and put it back in. I've pored over our code, and there is nothing I can see that would persist across a SW reset--yet would be cleared via a power cycle--that could prevent the processor from sleeping.
Some other important notes:
- the accelerometer is an obvious culprit--since it wouldn't be reset when the 833 is--but it's disabled, and I've also confirmed that an improperly handled interrupt does not cause the processor to remain on (the int is edge triggered, so even if it's not cleared on the accelerometer it wouldn't fire again). There is also no mode of operation of the accelerometer itself that would draw this kind of current.
- Normal operation continues after the error manifests, and timing is unaffected. No resets or other anomalous behavior occurs when the event starts--it just suddenly happens
- The issue only occurs when the tag is moved--and I believe only when the flag is taken off/put on the equipment. This makes me think some kind of mechanical shock--the magnets are quite strong--causes the problem, but tags that I've inspected don't have any obvious damage (and replacing the battery causes them to return to normal operation)
- The programming header pads (SCLK,SDIO, VCC, GND) are close to the battery, but none of the ones I inspected were touching it. It may be possible for the battery to very briefly touch the pads under the right conditions
- I've considered other rogue interrupts, but the only ones in use are: the GPIO for the accelerometer, the SAADC (used to sample the battery voltage), the radio (I know it's not active because the code toggles the POWER register after each use and ensures all ints are cleared), the WDT, and SWI0 for the app timer. Also: seems like a reset would clear any stray interrupts.
- We've been completely unable to replicate the problem, and we've never run across this in any prior testing.
Through a run of ridiculously bad luck I've been unable to get my hands on a tag that is both alive and currently malfunctioning, so I haven't been able to tie into one yet. That's my next move (unfortunately I have to wait for one to exhibit the problem then arrange travel and fly out to do it), but in the meanwhile I'm curious if anyone is aware of anything in the nordic that could cause this. My current lines of thought are:
- Sudden mechanical shock causes battery to shift and briefly contact programming pads, which somehow places tag in debug mode...?
- same as above, but battery either momentarily loses contact with holder or contacts VCC/GND, which causes the PMU to enter a strange state
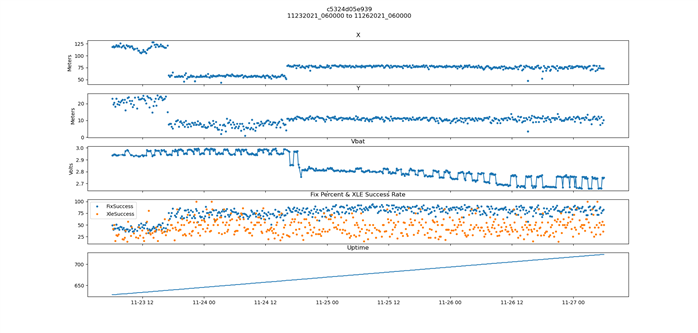
I've attached an image of the malfunction occurring. About a third of the way across, you can see the Vbat suddenly drops and then begins a steady ramp down. The start roughly coincides with the tag moving (note the change in X/Y). I believe in this instance the equipment the tag was on moved to a new workstation, then shortly after the flag was pulled off and moved nearby (workers have to do that occasionally) and that's when it started.
Until I can get my hands on one that's currently malfunctioning I'm stumped, so thanks in advance for any ideas!
Mark

