hello Nordic
i am working with nrf52832, with zephyr, ncs v1.7.1,
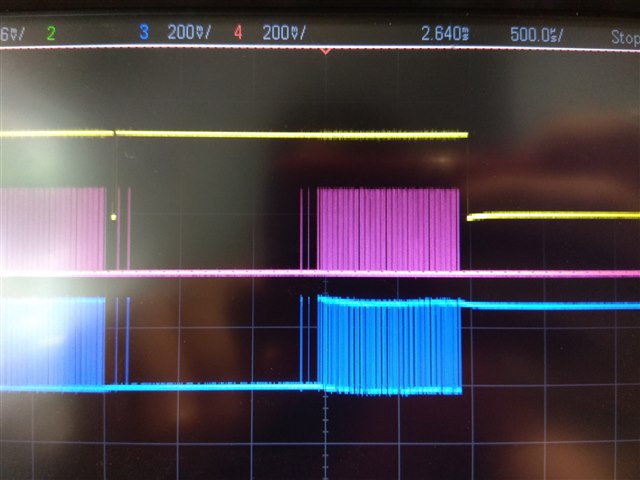
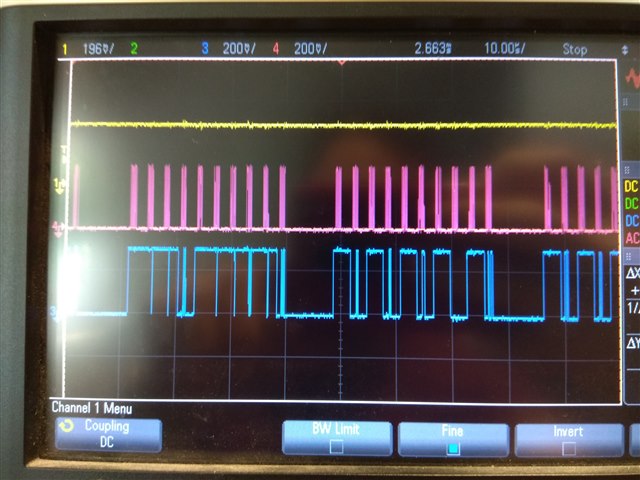
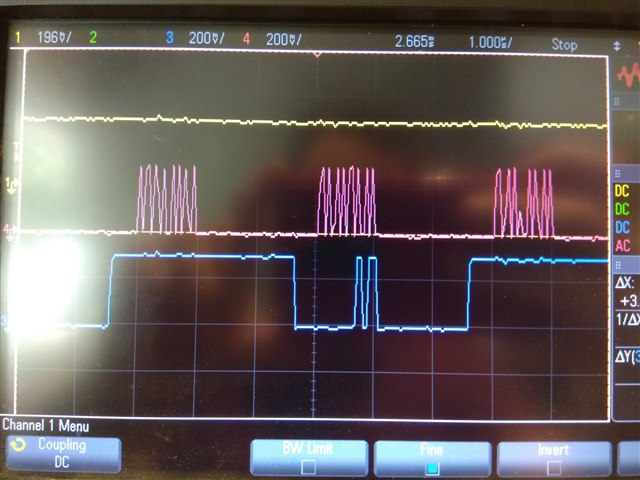
the device has a sensor that sample at 26khz each sample is 3 channels of 2 bytes data. the sensor use spi1 and has high thread priority (cooperative) the samples are then stream via a double buffer to the flash which uses spi2.
when tying to write a page (256 bytes) to the flash at a test in the beginning of the app it take 1ms to write that page but when trying to write within the app, while the other sensor is sampling, it takes 3ms and also i get a BUS FAULT. here is the log:
[00000018] <err> os: ***** BUS FAULT *****
[00000018] <err> os: Unstacking error
[00000018] <err> os: ***** HARD FAULT *****
[00000018] [1;31m<err> os: Fault escalation (see below)
[00000018] <err> os: ***** BUS FAULT *****
[00000018] <err> os: Precise data bus error
[00000018] <err> os: BFAR Address: 0xfe80fec0
[00000018] <err> os: r0/a1: 0x2000bef0 r1/a2: 0xfe80fec0 r2/a3: 0xfe80ff28
[00000018] <err> os: r3/a4: 0x2000beef r12/ip: 0xfa000000 r14/lr: 0x00016d79
[00000018] <err> os: xpsr: 0x81000005
[00000018] <err> os: s[ 0]: 0x00000000 s[ 1]: 0x00000000 s[ 2]: 0x00000000 s[ 3]: 0x00000000
[00000018] <err> os: s[ 4]: 0x00000000 s[ 5]: 0x00000000 s[ 6]: 0x00000000 s[ 7]: 0x00000000
[00000018] <err> os: s[ 8]: 0x00000000 s[ 9]: 0x00000000 s[10]: 0x00000000 s[11]: 0x00000000
[00000018] <err> os: s[12]: 0x00000000 s[13]: 0x00000000 s[14]: 0x00000000 s[15]: 0x00000000
[00000018] <err> os: fpscr: 0x20001d78
[00000018] <err> os: Faulting instruction address (r15/pc): 0x0003ef10
[00000018] <err> os: >>> ZEPHYR FATAL ERROR 0: CPU exception on CPU 0
[00000018] <err> os: Fault during interrupt handling
[00000018] <err> os: Current thread: 0x20003210 (unknown)
[00000018] <err> fatal_error: Resetting system
*** Booting Zephyr OS build v2.6.99-ncs1-1 ***
now i do have in the app another driver that uses spi (at the same time (getting samples and writing samples to flash), but it uses a different instance of spi so i don't see why it shell create such a delay .. here is my complete .dts file:
// Copyright (c) 2022 Nordic Semiconductor ASA
// SPDX-License-Identifier: Apache-2.0
/dts-v1/;
#include <nordic/nrf52832_qfaa.dtsi>
/ {
model = "halo_ep2";
compatible = "halo-ep2";
chosen {
zephyr,sram = &sram0;
zephyr,flash = &flash0;
zephyr,code-partition = &slot0_partition;
nordic,pm-ext-flash = &augu_flash_is25lp128;
};
sensors_on: sensors_on_node {
compatible = "augury,gpio-power";
power_gpios = <&gpio0 22 GPIO_ACTIVE_LOW>;
label = "SENSORS_ON";
status = "okay";
#power_resource-cells = <0>;
};
flash_on: flash_on_node {
compatible = "augury,gpio-power";
power_gpios = <&gpio0 23 (GPIO_PULL_UP | GPIO_ACTIVE_LOW)>;
label = "FLASH_ON";
status = "okay";
#power_resource-cells = <0>;
};
leds {
compatible = "gpio-leds";
led0_red: led_0 {
gpios = <&gpio0 25 GPIO_ACTIVE_HIGH>;
label = "RED_LED_0";
};
led1_orange: led_1 {
gpios = <&gpio0 26 GPIO_ACTIVE_HIGH>;
label = "ORANGE_LED_1";
};
led2_green: led_2 {
gpios = <&gpio0 27 GPIO_ACTIVE_HIGH>;
label = "GREEN_LED_2";
};
};
aliases {
led0-red = &led0_red;
led1-orange = &led1_orange;
led2-green = &led2_green;
};
};
&adc {
status ="okay";
};
&gpiote {
status ="okay";
};
&gpio0 {
status ="okay";
};
&spi1 {
compatible = "nordic,nrf-spim";
status = "okay";
sck-pin = <20>;
mosi-pin = <14>; // p0.14
miso-pin = <16>; // p0.16
cs-gpios = <&gpio0 13 GPIO_ACTIVE_LOW>;
iis3dwb@0 {
compatible = "st,iis3dwb";
reg = <0>;
int1_gpios = <&gpio0 11 (GPIO_ACTIVE_HIGH | GPIO_PULL_DOWN)>;
int2_gpios = <&gpio0 12 (GPIO_ACTIVE_HIGH | GPIO_PULL_DOWN)>;
label = "IIS3DWB";
power_resources = <&sensors_on>;
spi-max-frequency = <8000000>;
};
};
&spi2 {
status = "okay";
sck-pin = <5>; // gpio 0 pin 5
mosi-pin = <4>; // gpio 0 pin 4
miso-pin = <2>; // gpio 0 pin 2
compatible = "nordic,nrf-spi";
cs-gpios = <&gpio0 3 (GPIO_PULL_UP | GPIO_ACTIVE_LOW)>;
augu_flash_is25lp128: augu_flash_is25lp128@0 {
compatible = "issi,augu_flash_is25lp128";
reg = <0>;
label = "AUGU_FLASH_IS25LP128";
power_resources = <&flash_on>;
jedec_id = [9d 60 18];
spi-max-frequency = <8000000>; //<133000000>;
page_size = <256>;
block_size = <65536>;
size = <0x8000000>;
};
};
&flash0 {
partitions {
compatible = "fixed-partitions";
#address-cells = <1>;
#size-cells = <1>;
mbr_partition: partition@0 {
label = "mbr";
reg = <0x00000000 0x00001000>;
};
boot_partition: partition@1000 {
label = "mcuboot";
reg = <0x1000 0xc000>;
};
slot0_partition: partition@d000 {
label = "image-0";
reg = <0xd000 0x6c800>;
};
slot1_partition: partition@79800 {
label = "image-1";
reg = <0x79800 0x800>;
};
storage_partition: partition@7a000 {
label = "storage";
reg = <0x7a000 0x6000>;
};
};
};
(running the app on another board with nrd52840, with nand flash that writes 2k each time, works well, so i don't know if it is a performance issue or something else.. i will also mention that the RAM take on the nrf52832 with zephyr and all is high:
[567/572] Linking C executable zephyr/zephyr.elf
Memory region Used Size Region Size %age Used
FLASH: 253604 B 419328 B 60.48%
SRAM: 60282 B 64 KB 91.98%
IDT_LIST: 0 GB 2 KB 0.00%
[568/572] Generating zephyr/mcuboot_primary_app.hex
[569/572] Generating zephyr/mcuboot_primary.hex
[570/572] Generating ../../zephyr/app_update.bin, ../../zephyr/app_signed.hex, ../../zephyr/app_test_update.hex, ../../zephyr/app_moved_test_update.hex
[571/572] Generating ../../zephyr/dfu_application.zip
[572/572] Generating zephyr/merged.hex
any idea why i get the BUS FAULT ?
p.s. i don't know if it has any affect but the page data is saved in a heap section previously allocated like so
K_HEAP_DEFINE(my_heap, 3072); // 256*3*2 = 1536 + safe buffer
int mem_heap_alloc(int size, struct k_mem_block *block)
{
block->data = NULL;
block->data = k_heap_alloc(&my_heap, size, K_NO_WAIT);
if (block->data == NULL)
{
return -ENOMEM;
}
return 0;
}
void mem_heap_free(struct k_mem_block *block)
{
k_heap_free(&my_heap, block->data);
}
and the call is for
mem_heap_alloc(with 2 page size)
like a double buffer for steaming the
data collected to flash, one page gets
fill with samples while the other is written to flash, in theaory
the other question i will leave for now it is also regarding a try to improve the current spi_nor_write function but anyhow it will not solve the 3ms issue and if it will remain on 1ms per page write as seen in the first test then we will be ok
we think it is a performance issue (which we don't see when the same code runs on nrf52840 with a nand flash, which also writes 2k each time and not 256 pages)
one of the possible solutions is to change the api of the sensor driver so instead of using many time fetch and get, to get one api for fetching a pointer to a buffer of the samples stored in the driver, another idea is to have the driver use easy dma to put the samples to a buffer in memory with an interrupt after reaching 256 bytes, and then write to flash from this buffer. any idea if there is some support for one of this operations in zephyr/ncs ?,
any ideas as for which is better ?
any ideas of beast way to do preferred one ?
hope to read from you soon
best regards
Ziv