Hi,
I have a nRF5340 using hci_ipc that has the following features:
- Central Role + Scanning (Multi-connection to nRF52840 peripherals)
- Peripheral Role
- QoS Channel Scanning
- Nordic Uart (Server + Client)
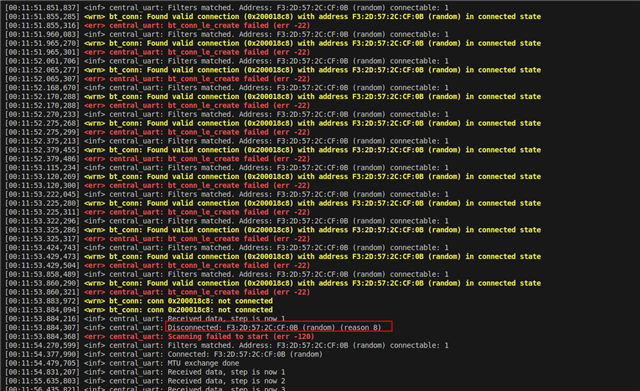
I am missing bluetooth supervision timeout events with the nRF53 with both ncs 2.7.0 and the upstream Zephyr BLE stack. (No disconnected callback using the Softdevice).
Problem Flow from Central perspective:
1) Scan and connect
2) Subscribe to NUS (cached handles - no discovery)
3) MTU Exchange
4) Send NUS data back and forth (~1.2Kb DTLS handshake)
5) Disconnect Peripheral with pending Central NUS GATT write (breakpoint peripheral nrf52 / power off / reset)
6) Observe no supervision timeout (4s) [This event expected, but doesn't happen]
7) Observe GATT write error 30s later
8) GATT error cleans up nus subscription, manually issue disconnect here
9) Observe no .disconnected callback
Setups used:
1) Initially we were on NCS 2.7.0 with the included hci_ipc using the ipc_radio sample with a few upstream network (not bluetooth) related cherrypicks. We had problems with this configuration missing disconnect events.
2) Now we're on a heavily cherrypicked SDK to get as close to Zephyr main upstream Bluetooth stack (from the last couple days) & the newest nrfx-lib softdevice+hci_ipc. We still had problems with this.
3) With the heavily cherrypicked SDK, we enabled SPLIT_SW_LL and do not miss these supervision timeout events with the same application code.
I am curious what layer these disconnect events are supposed to get propagated through `zephyr/drivers/bluetooth/ipc/ipc.c` when using `hci_ipc`.
I have not yet been able to make a minimum viable example, but am working towards this.
I made a Zephyr discord post regarding this on #nordic for additional context, which I tried to summarize here.
https://discord.com/channels/720317445772017664/883445320812466209/1283513590606860318
Let me know if I can provide additional information,
Jeff