Hello,
While working with ai.lab.nordicsemi.com and the Neuton library, I encountered several limitations related to the feature extraction workflow and the provided function interfaces. I would like to request clarification and possible support.
In my project, I already have a custom feature extraction algorithm that is optimized for my specific application and significantly improves performance. Therefore, I prefer not to use the built-in feature extraction pipeline provided by the model. Instead, I would like to use pre-extracted feature data for model training or inference. This would also minimize changes to my existing codebase, as I would only need to pass the extracted features directly to the model.
However, I am facing the following issues:
-
The Neuton functions are provided as a static .a library (e.g., libnrf_edgeai_cortex-m4.a). The function prototypes cannot be modified, which makes it difficult to adapt the interface to fit a custom feature extraction pipeline.
-
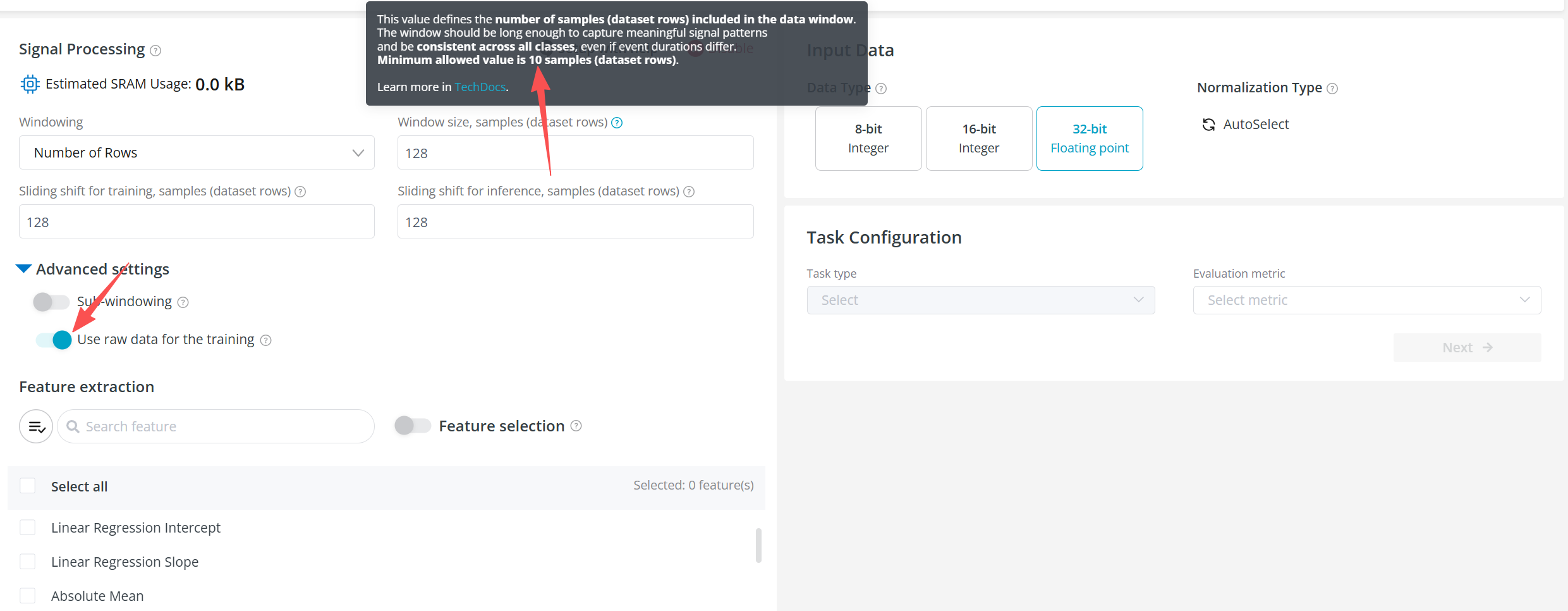
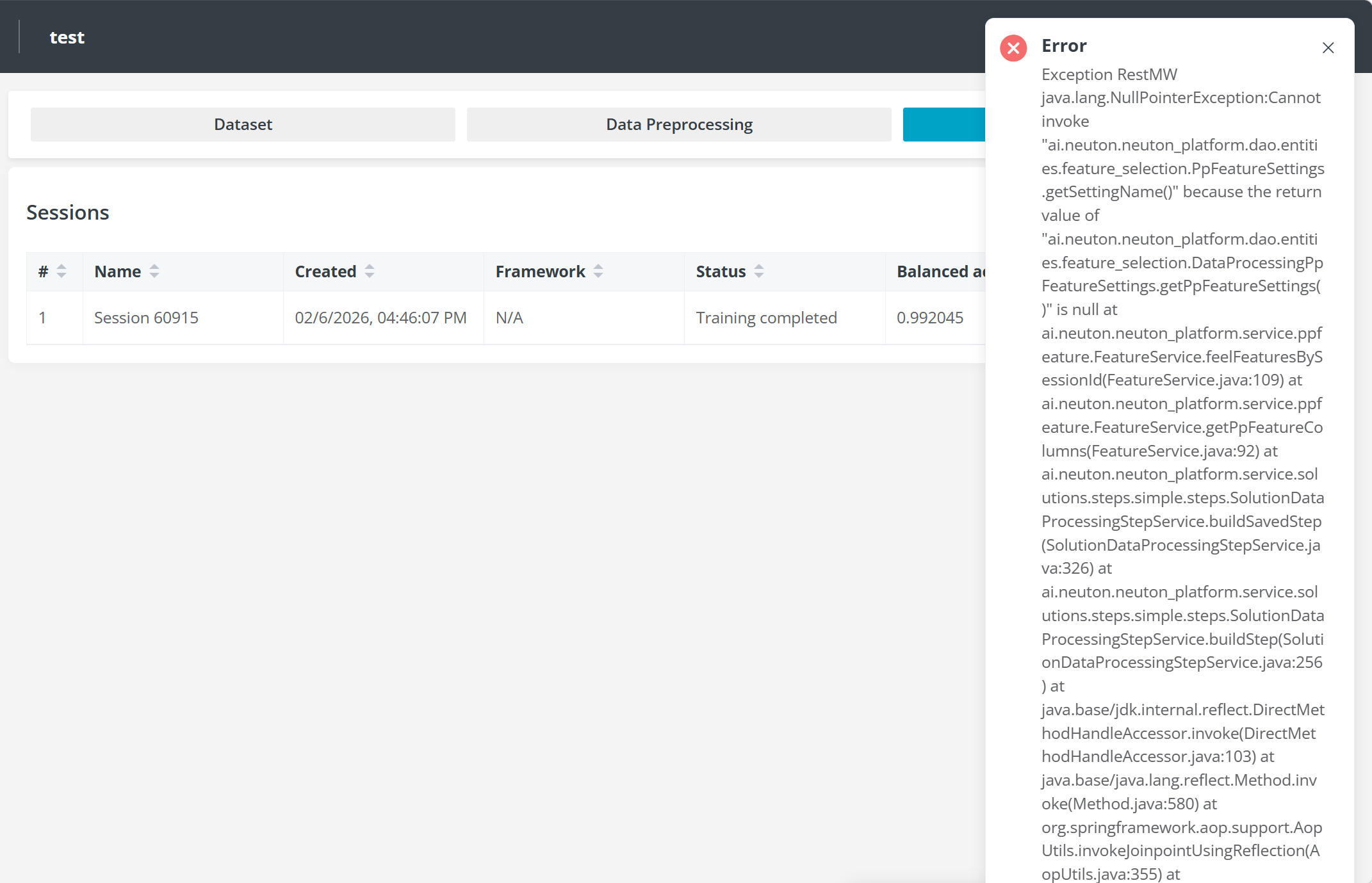
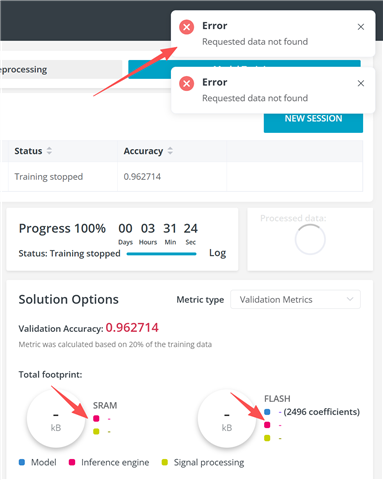
On ai.lab, it appears that training must go through the platform’s built-in feature extraction workflow. When selecting “Use raw data for the training” in Advanced Settings, there is a constraint that the minimum window size must be greater than 10 rows. This does not align with my current setup, where feature extraction has already been completed and the data structure differs from raw time-series input.
Based on this, I would like to ask:
-
Is it possible to expose more configurable interfaces in the .a library, or provide a customizable version that allows developers to adapt the function interfaces to their project requirements?
-
Could ai.lab provide an option to upload and train models using externally extracted feature data, instead of requiring the use of the built-in feature extraction pipeline?
If there are existing solutions, recommended approaches, or workarounds to achieve this, I would greatly appreciate your guidance.
Thank you for your support.