I've got another question concerning a timeslot application.
In our timeslot application which is based on the nRF Mesh SDK timeslot.c implementation I noticed that if a BLE connection is active with a connection interval of 7.5ms, the softdevice did not grant any timeslots. I noticed that the cause of this was that the requested timeslot length requested at the end of a timeslot was 14000us and therefore too long to fit into the 7.5ms connection interval. This resultd in the timeslot being canceled via invocation of the softdevice event handler with NRF_EVT_RADIO_CANCELED.
The handling of this event was a call to sd_radio_request() but using the same parameters that were canceled. This resulted in the softdevice event handler being called repeatedly with NRF_EVT_RADIO_CANCELED until either the BLE connection parameters were changed or the central disconnected.
To avert this behaviour I changed the request parameters to the values that were used in case of a NRF_EVT_RADIO_BLOCKED:
m_radio_request_earliest.request_type = NRF_RADIO_REQ_TYPE_EARLIEST; m_radio_request_earliest.params.earliest.hfclk = NRF_RADIO_HFCLK_CFG_NO_GUARANTEE; m_radio_request_earliest.params.earliest.priority = NRF_RADIO_PRIORITY_NORMAL; m_radio_request_earliest.params.earliest.length_us = 3800; m_radio_request_earliest.params.earliest.timeout_us = 15000;
This resulted in the timeslot being granted again after NRF_EVT_RADIO_CANCELED occurred.
I then realised that after changing the connection interval to 50ms with a slave latency of 2, timeslots get repeatedly blocked for a duration of 5ms (during the connection event) and only then are they being granted again. See the following chart:
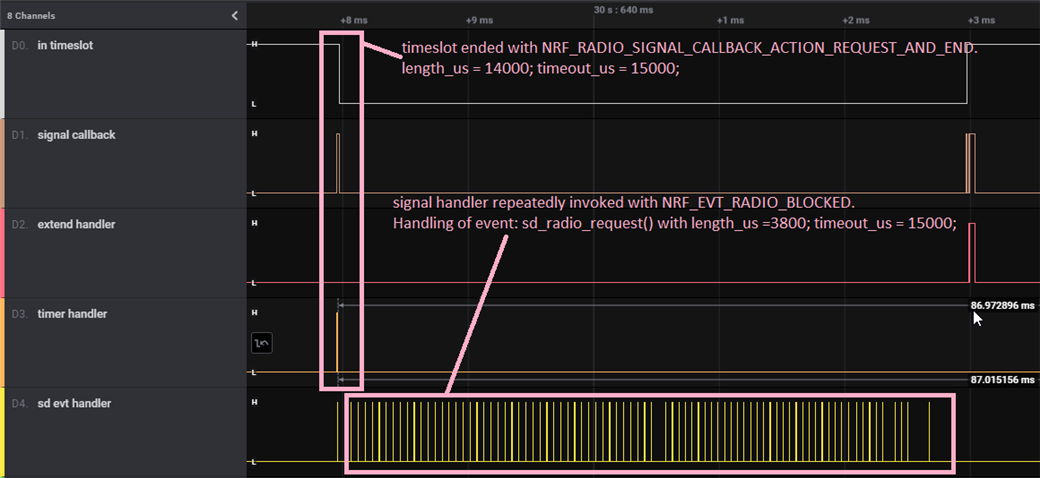
I thought this behaviour looks odd and inefficient. Ideally, I expect the softdevice to not invoke the BLOCKED event, since the timeout - from my understanding - should only occur after 15000us? Invoking sd_radio_request() when handling the BLOCKED event with a length_us of 3800 and a timeout_us of 14000, I definitely don't expect the event handler to be invoked every ~50us!
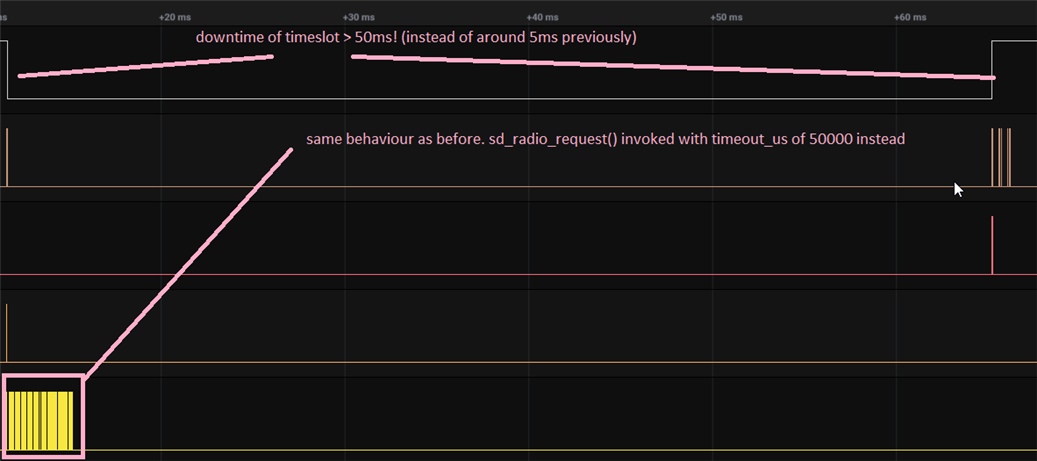
So I tried to play around with the timeout_us parameter of the nrf_radio_request_t structure, but did not find a viable solution, in fact I only made it worse. When increasing the timeout_us e.g. to 50000, I noticed that the described behaviour occurs for a bit and then disappears, but the timeslot is only started after a total downtime of about 50ms! This drastically reduces the availability of our proprietary radio protocol.
- Is there a clean way to avert these continuous BLOCKED events while still maximising timeslot duration?
- Can you elaborate on the difference between the BLOCKED and CANCELED events?
- What implications does/should changing the timeout of a radio request have?
By the way, this is all on an nRF52832 running S132 7.2.0.