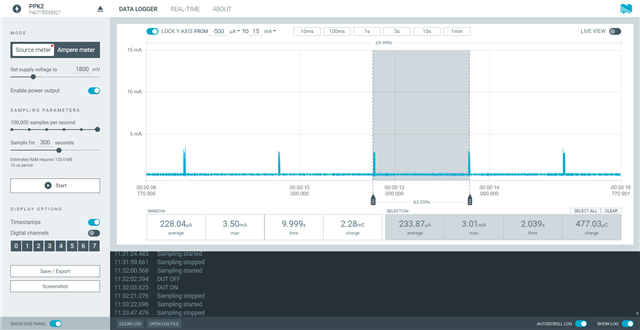
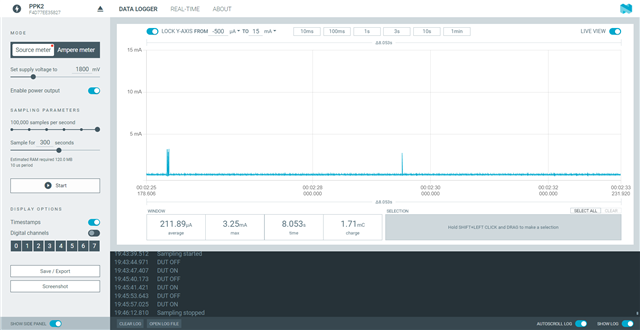
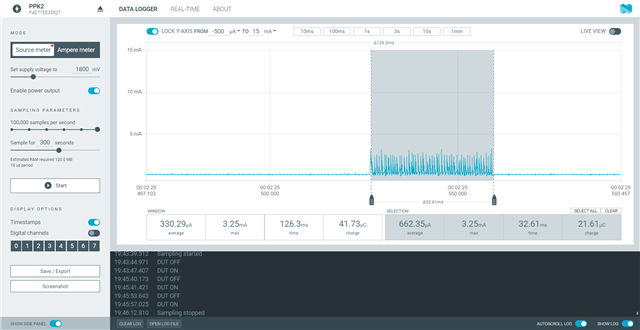
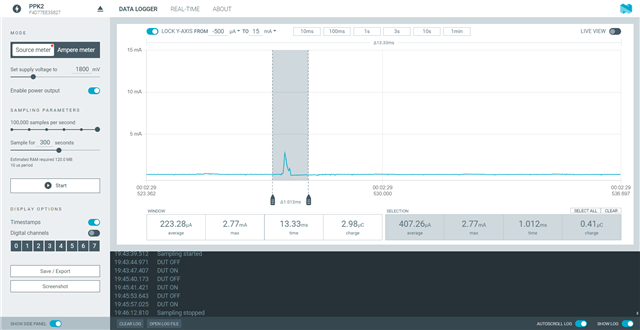
Hello All,
I am getting these ~3.5mA current spikes very 4 seconds and I can't seem to figure what the cause of them is. some of the spikes have a single spike/pulse while other have multiple. please see the attached images. I have commented out everything except the while in the main function and no difference. I have also commented out the enabling of the DCDC and still the same issue. any help would be greatly appreciate. I have a feeling its in the project config setting but tried commenting out what I thought may be the cause but no change either.
I am using a custom board with 52833 and nRF Connect SDK 2.0.0. the board does have other ICs(hall sensors) but I measured their consumption and had no spikes.
while (1) {
//k_sleep(K_SECONDS(1));
//k_msleep(500);
__WFE();
}
my project config file
#CONFIG_DK_LIBRARY=y # Config logger CONFIG_LOG=n CONFIG_USE_SEGGER_RTT=n CONFIG_LOG_BACKEND_RTT=n CONFIG_LOG_BACKEND_UART=n CONFIG_LOG_DEFAULT_LEVEL=3 CONFIG_DEBUG_OPTIMIZATIONS=n # CONFIG_LOG_MODE_IMMEDIATE=n CONFIG_SERIAL=n CONFIG_CONSOLE=n CONFIG_UART_CONSOLE=n # Config Bluetooth CONFIG_BT=y ##CONFIG_BT_DEBUG_LOG=y ##CONFIG_BT_SMP=y CONFIG_BT_PERIPHERAL=y CONFIG_BT_DIS=y CONFIG_BT_DIS_PNP=n # CONFIG_BT_BAS=y # CONFIG_BT_HRS=y CONFIG_BT_DEVICE_NAME="XXX Sensor" CONFIG_BT_DEVICE_APPEARANCE=0 #CONFIG_BT_DEVICE_APPEARANCE=833 CONFIG_BT_LL_SOFTDEVICE=y CONFIG_BT_MAX_CONN=1 CONFIG_BT_GAP_PERIPHERAL_PREF_PARAMS=y CONFIG_BT_PERIPHERAL_PREF_MIN_INT=40 CONFIG_BT_PERIPHERAL_PREF_MAX_INT=45 CONFIG_BT_BUF_ACL_RX_SIZE=251 CONFIG_BT_BUF_ACL_TX_SIZE=251 CONFIG_BT_L2CAP_TX_MTU=247 CONFIG_BT_CTLR_DATA_LENGTH_MAX=251 CONFIG_BT_BUF_ACL_TX_COUNT=10 # CONFIG_CLOCK_CONTROL_NRF_FORCE_ALT=y wh CONFIG_CLOCK_CONTROL_NRF=y CONFIG_CLOCK_CONTROL_NRF_K32SRC_RC=y CONFIG_CLOCK_CONTROL_NRF_K32SRC_XTAL=n # CONFIG_CLOCK_CONTROL_NRF_K32SRC_XTAL is not set # CONFIG_CLOCK_CONTROL_NRF_K32SRC_SYNTH is not set # CONFIG_CLOCK_CONTROL_NRF_K32SRC_EXT_LOW_SWING is not set # CONFIG_CLOCK_CONTROL_NRF_K32SRC_EXT_FULL_SWING is not set CONFIG_CLOCK_CONTROL_NRF_K32SRC_RC_CALIBRATION=y CONFIG_CLOCK_CONTROL_NRF_CALIBRATION_LF_ALWAYS_ON=y CONFIG_CLOCK_CONTROL_NRF_K32SRC_500PPM=y CONFIG_GPIO_AS_PINRESET=n CONFIG_GPIO=y CONFIG_GPIO_NRFX=y CONFIG_NRFX_GPIOTE=y CONFIG_SPI=y #CONFIG_ASSERT=y #CONFIG_NRFX_PRS_BOX_2=y # CONFIG_NRFX_TIMER0=y CONFIG_NRFX_TIMER1=y CONFIG_NRFX_TIMER2=y CONFIG_NRFX_TIMER3=y CONFIG_NRFX_TIMER4=y CONFIG_NRFX_PPI=y CONFIG_NRFX_GPIOTE_NUM_OF_EVT_HANDLERS=2 CONFIG_NRFX_SPIM0=y CONFIG_NRFX_SPIM1=y CONFIG_COUNTER=y #CONFIG_COUNTER_TIMER1=y CONFIG_NRFX_RTC2=y CONFIG_NRFX_POWER=y ##CONFIG_PM=y # Required to disable default behavior of deep sleep on timeout ##CONFIG_PM_DEVICE=y #CONFIG_GPIO=y # Optional select RAM retention (nRF52 only) #CONFIG_APP_RETENTION=y